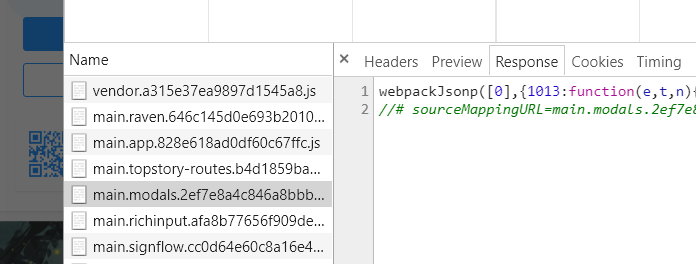
[quote=引用 1 楼 ambit_tsai 的回复:] 在JS文件中找找,都写在JS文件中了
在JS文件中找找,都写在JS文件中了
37,738
社区成员
34,210
社区内容
加载中
试试用AI创作助手写篇文章吧


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享