社区
脚本语言
帖子详情
初学者,爬虫文件下载问题!
byxiaoxie
2018-07-07 02:21:11
下载连接:http://127.0.0.1/down/1
正常浏览器打开后直接跳文件下载,python怎么把这个文件下载出来,利用request.urlopen下载出来的网页,不是文件,求大神教下!
...全文
175
5
打赏
收藏
初学者,爬虫文件下载问题!
下载连接:http://127.0.0.1/down/1 正常浏览器打开后直接跳文件下载,python怎么把这个文件下载出来,利用request.urlopen下载出来的网页,不是文件,求大神教下!
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
5 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
byxiaoxie
2018-07-07
打赏
举报
回复
谢谢你的回复,问题已解决了,我使用了无头浏览器访问可以了,应该是反盗链来的!
silence cc
2018-07-07
打赏
举报
回复
抓包看看是不是重定向,找到真正的下载地址
byxiaoxie
2018-07-07
打赏
举报
回复
我尝试使用了 requets.get() 下载出来的是HTML不是文件,他这个用浏览器访问是跳下载 test.txt
silence cc
2018-07-07
打赏
举报
回复
requests模块没有urlopen方法吧,urllib2才会有urlopen方法
silence cc
2018-07-07
打赏
举报
回复
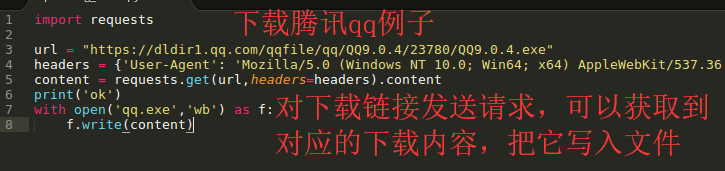
使用requests.get方法直接发送请求,获取后下载的内容,再写入文件保存
perl_
爬虫
脚本
结合中英两版网站信息,适合perl
初学者
学习模块和哈希数组等。文件为txt格式代码在其中。-Reptile Exchange Bank. Binding ounce version of the site information for beginners to learn perl module and hash ...
喜马拉雅音频
爬虫
神器2021年最新版.py
双击py文件后,粘贴入喜马拉雅专辑网址,即可在当前目录下建立本专辑的文件夹,并按顺序编号下载音频文件。每一块代码都有详细注释,尤其适合
初学者
练习。经典好用!
SpringMVC入门视频课程(适合
初学者
的教程)
本课程以通俗易懂的方式讲解SpringMVC核心技术,适合
初学者
的教程,让你少走弯路! 1.SpringMVC简介和实现原理、Controller详解、方法的参数 2.JSR303数据校验、类型转换、统一异常处理 3.拦截器、处理AJAX、文件...
JAVA上百实例源码以及开源项目
基于JAVA的UDP服务器模型源代码,内含UDP服务器端模型和UDP客户端模型两个小程序,向JAVA
初学者
演示UDP C/S结构的原理。 简单聊天软件CS模式 2个目标文件 一个简单的CS模式的聊天软件,用socket实现,比较简单。 ...
爬虫
案例-实现翻译功能
初学者
入门
爬虫
!!!
脚本语言
37,720
社区成员
34,239
社区内容
发帖
与我相关
我的任务
脚本语言
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
复制链接
扫一扫
分享
社区描述
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
试试用AI创作助手写篇文章吧
+ 用AI写文章





 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享