社区
脚本语言
帖子详情
Python怎么获取京东的抢券URL?
yananjava
2018-07-08 10:51:09
Python怎么获取京东的抢券URL?
...全文
824
1
打赏
收藏
Python怎么获取京东的抢券URL?
Python怎么获取京东的抢券URL?
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
1 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
屎克螂
2018-07-09
打赏
举报
回复
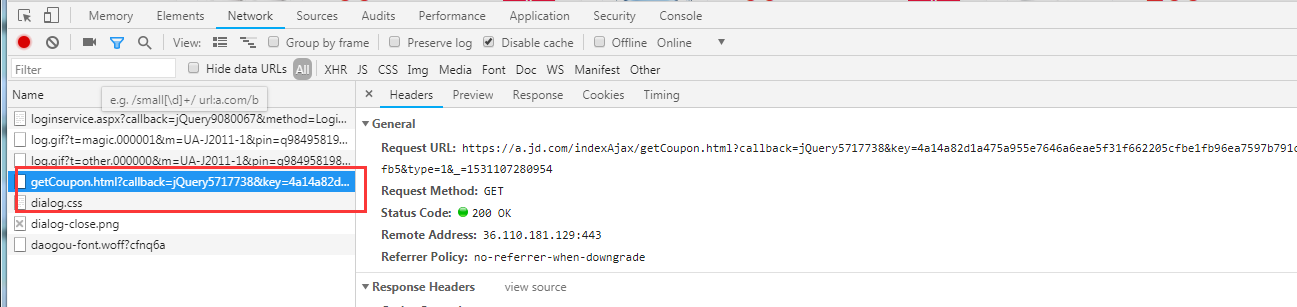
要登入,登入比较麻烦,有一道js加密,不过你可以试下selenium
python
京东
预约抢购_
Python
参考代码:
京东
抢券
脚本
本文介绍了如何使用
Python
实现
京东
抢券
脚本,包括
获取
券的
URL
、Referer和Cookie等关键参数,以及参考代码示例,通过requests库和selenium库进行定时
抢券
操作。
【
Python
】
Python
脚本实现
抢券
本文介绍了一种使用
Python
的Requests库实现自动抢购
京东
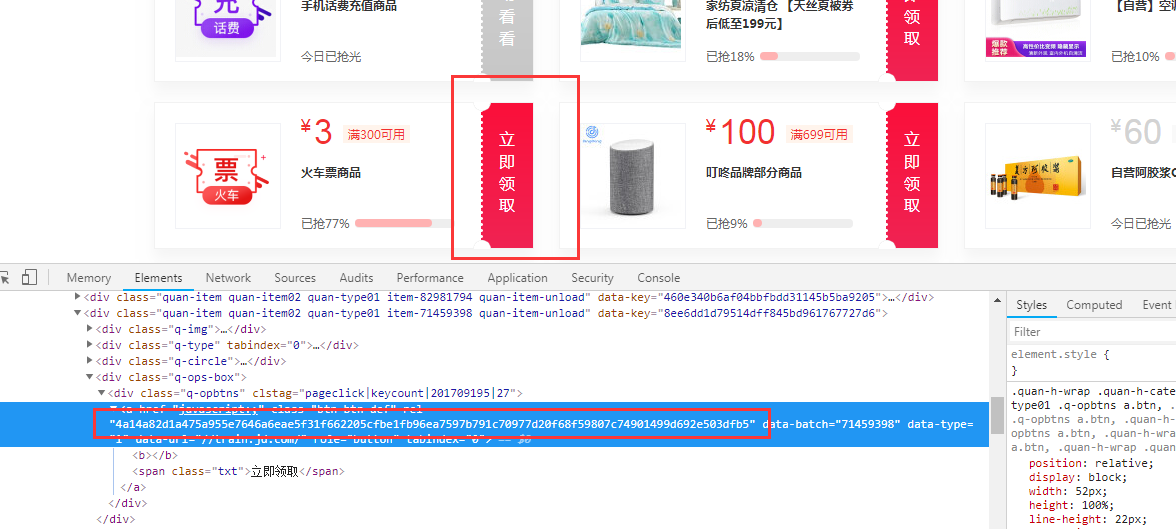
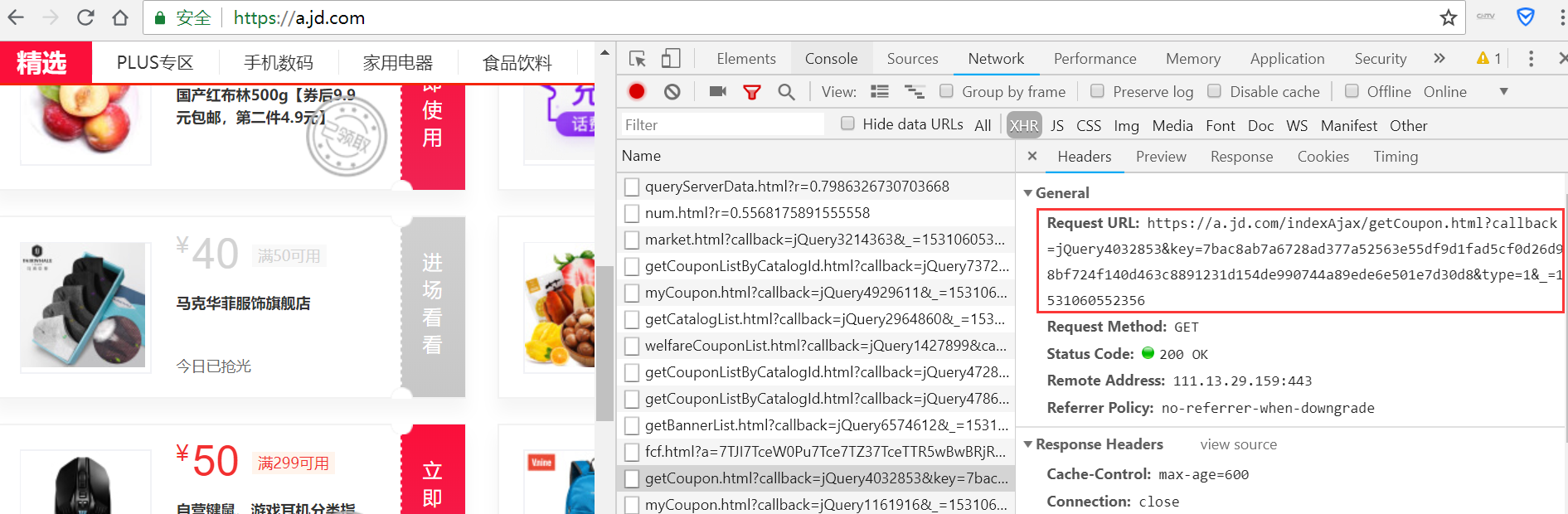
优惠券的方法。通过解析浏览器开发者工具
获取
必要的参数,如
URL
、Cookie和Referer,再利用Requests的Session对象保持状态,最终实现了在设定时间自动
抢券
的功能。
如何使用
python
抢优惠券-
Python
写一个
京东
抢券
脚本
本文介绍了一个尝试使用
Python
脚本自动抢
京东
图书满200减100优惠券的方法。作者通过
获取
URL
、设置Cookie及定时任务实现自动
抢券
,但最终未能成功。
python
京东
抢券
_
Python
写一个
京东
抢券
脚本
作者看到
京东
图书满200减100优惠券,因手动抢不到便用
Python
写脚本。关键步骤包括
获取
优惠券
url
和cookie、定时调用。代码展示了请求函数、cookie处理等,测试发现请求频率无限制,但最终仍未抢到券。
618!
python
京东
PC 版
抢券
程序
本文介绍了用
Python
编写的
京东
PC版
抢券
程序。先
获取
并检测二维码是否扫码,再验证二维码实现登录。接着通过抓包
获取
优惠券列表,最后根据列表中的key领取优惠券,还给出了各步骤的代码及示例结果。
脚本语言
37,738
社区成员
34,210
社区内容
发帖
与我相关
我的任务
脚本语言
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
复制链接
扫一扫
分享
社区描述
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享