37,721
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
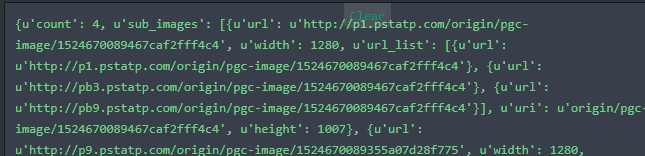
分享{\"count\":4,\"sub_images\":[{\"url\":\"http:\\/\\/p1.pstatp.com\\/origin\\/pgc-image\\/1524670089467caf2fff4c4\",\"width\":1280,\"url_list\":[{\"url\":\"http:\\/\\/p1.pstatp.com\\/origin\\/pgc-image\\/1524670089467caf2fff4c4\"},{\"url\":\"http:\\/\\/pb3.pstatp.com\\/origin\\/pgc-image\\/1524670089467caf2fff4c4\"},{\"url\":\"http:\\/\\/pb9.pstatp.com\\/origin\\/pgc-image\\/1524670089467caf2fff4c4\"}],\"uri\":\"origin\\/pgc-image\\/1524670089467caf2fff4c4\",\"height\":1007},{\"url\":\"http:\\/\\/p9.pstatp.com\\/origin\\/pgc-image\\/1524670089355a07d28f775\",\"width\":1280,\"url_list\":[{\"url\":\"http:\\/\\/p9.pstatp.com\\/origin\\/pgc-image\\/1524670089355a07d28f775\"},{\"url\":\"http:\\/\\/pb1.pstatp.com\\/origin\\/pgc-image\\/1524670089355a07d28f775\"},{\"url\":\"http:\\/\\/pb3.pstatp.com\\/origin\\/pgc-image\\/1524670089355a07d28f775\"}],\"uri\":\"origin\\/pgc-image\\/1524670089355a07d28f775\",\"height\":900},{\"url\":\"http:\\/\\/p3.pstatp.com\\/origin\\/pgc-image\\/1524670089412445c95fe1e\",\"width\":1280,\"url_list\":[{\"url\":\"http:\\/\\/p3.pstatp.com\\/origin\\/pgc-image\\/1524670089412445c95fe1e\"},{\"url\":\"http:\\/\\/pb9.pstatp.com\\/origin\\/pgc-image\\/1524670089412445c95fe1e\"},{\"url\":\"http:\\/\\/pb1.pstatp.com\\/origin\\/pgc-image\\/1524670089412445c95fe1e\"}],\"uri\":\"origin\\/pgc-image\\/1524670089412445c95fe1e\",\"height\":1022},{\"url\":\"http:\\/\\/p9.pstatp.com\\/origin\\/pgc-image\\/152467008944401ff089475\",\"width\":1280,\"url_list\":[{\"url\":\"http:\\/\\/p9.pstatp.com\\/origin\\/pgc-image\\/152467008944401ff089475\"},{\"url\":\"http:\\/\\/pb1.pstatp.com\\/origin\\/pgc-image\\/152467008944401ff089475\"},{\"url\":\"http:\\/\\/pb3.pstatp.com\\/origin\\/pgc-image\\/152467008944401ff089475\"}],\"uri\":\"origin\\/pgc-image\\/152467008944401ff089475\",\"height\":1151}],\"max_img_width\":1280,\"labels\":[\"\\u51b7\\u996e\",\"\\u7f8e\\u5973\",\"\\u5386\\u53f2\"],\"sub_abstracts\":[\"\\u5357\\u4eac\\u8def\\u5df2\\u6709100\\u591a\\u5e74\\u7684\\u5386\\u53f2\\uff0c\\u5b83\\u7684\\u524d\\u8eab\\u662f\\\"\\u6d3e\\u514b\\u5f04\\\"\\uff0c1865\\u5e74\\u6b63\\u5f0f\\u547d\\u540d\\u4e3a\\u5357\\u4eac\\u8def\\u3002\\u56fe\\u4e3a\\u4e24\\u5916\\u56fd\\u7f8e\\u5973\\u559d\\u51b7\\u996e\\u3002\\uff08\\u56fe\\u7247\\u6765\\u81ea\\u4e1c\\u65b9IC\\uff09\",\"\\u56fe\\u4e3a\\u5357\\u4eac\\u8def\\u6b65\\u884c\\u8857\\u4e0a\\u7684\\u5916\\u56fd\\u53cb\\u4eba\\u4e00\\u8def\\u4e0e\\u51b7\\u996e\\u76f8\\u4f34\\u3002\\uff08\\u56fe\\u7247\\u6765\\u81ea\\u4e1c\\u65b9IC\\uff09\",\"\\u4e0e\\u51b7\\u996e\\u4e3a\\u4f34\\u3002\\uff08\\u56fe\\u7247\\u6765\\u81ea\\u4e1c\\u65b9IC\\uff09\",\"\\u5929\\u6c14\\u786e\\u5b9e\\u6709\\u70b9\\u70ed\\u3002\\uff08\\u56fe\\u7247\\u6765\\u81ea\\u4e1c\\u65b9IC\\uff09\"],\"sub_titles\":[\"\\u5357\\u4eac\\u8def\\u6b65\\u884c\\u8857\\u8857\\u62cd\",\"\\u5357\\u4eac\\u8def\\u6b65\\u884c\\u8857\\u8857\\u62cd\",\"\\u5357\\u4eac\\u8def\\u6b65\\u884c\\u8857\\u8857\\u62cd\",\"\\u5357\\u4eac\\u8def\\u6b65\\u884c\\u8857\\u8857\\u62cd\"]}
def get_image_link(image_html):
soup = BeautifulSoup(image_html, 'lxml')
title = soup.select("title")[0].text
print(title)
image_patt = re.compile('gallery: JSON.parse\((.*?)\)', re.S)
# image_list = re.search(image_patt, image_html).group(1).replace("\\", "")
image_list = re.search(image_patt, image_html).group(1)
# print(image_list)
image_json =[color= json.loads(json.loads(image_list))
print(image_json)
sub_images = image_json['sub_images']
images = [item.get('url') for item in sub_images]
print(images)

json.decoder.JSONDecodeError: Expecting property name enclosed in double quotes: line 1 column 2 (char 1)
以下代码是爬取今日头条上一组图片的链接,我找到的图片链接信息在doc下
# 先获取网页内容
def get_image_group(html_url):
try:
res = requests.get(html_url)
if res.status_code == 200:
return res.text
return None
except RequestException:
print("请求详情页出错")
return None
# 找到要抓取的图片链接所在位置,并解析
def get_image_link(image_html):
soup = BeautifulSoup(image_html, 'lxml')
title = soup.select("title")[0].text
print(title)
image_patt = re.compile('gallery: JSON.parse\(\"(.*?)\"\)', re.S)
# image_list = re.search(image_patt, image_html).group(1).replace("\\", "")
image_list = re.search(image_patt, image_html).group(1)
print(image_list)
image_json = json.loads(image_list)
sub_images = image_json['sub_images']
images = [item.get('url') for item in sub_images]
print(images)
def main():
image_info = get_image_group("https://www.toutiao.com/a6548409069143589389/")
get_image_link(image_info)

json.decoder.JSONDecodeError: Expecting property name enclosed in double quotes: line 1 column 2 (char 1)
json.decoder.JSONDecodeError: Expecting property name enclosed in double quotes: line 1 column 2 (char 1)
# encoding: utf-8
import json
data = json.loads(json_str)
print(data)