我修改了一下,发现还需要很长很长时间,不知具体怎么修改才好 [/quote]
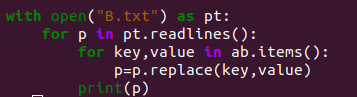
不要对ab.items进行循环,他数据太多了,可以尝试将B.txt的数据进行拆分,举个例子,以空格拆分:
def replace():
ab = {}
lines = []
with open("A.txt") as f:
for a in f.readlines():
k = a.strip("\n").split(" ")
ab[k[0]] = k[1]
with open("B.txt") as pt:
for line in pt.readlines():
array = line.strip("\n").split(" ")
newline = array[0]
for value in array[1:]:
newline +=" "+ab[value]
lines.append(newline+"\n")
with open("C.txt", "w+") as f:
f.writelines(lines)[/quote]
谢谢大神,6秒不到就完成替换了
我修改了一下,发现还需要很长很长时间,不知具体怎么修改才好 [/quote]
不要对ab.items进行循环,他数据太多了,可以尝试将B.txt的数据进行拆分,举个例子,以空格拆分:
def replace():
ab = {}
lines = []
with open("A.txt") as f:
for a in f.readlines():
k = a.strip("\n").split(" ")
ab[k[0]] = k[1]
with open("B.txt") as pt:
for line in pt.readlines():
array = line.strip("\n").split(" ")
newline = array[0]
for value in array[1:]:
newline +=" "+ab[value]
lines.append(newline+"\n")
with open("C.txt", "w+") as f:
f.writelines(lines)



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享





 [/quote]
[/quote]




