

37,741
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

# import xlrd
import xlwt
# from xlutils.copy import copy
# import os
# from builtins import str
# readOnlyBook = open_workbook('E:\\123.xlsx')
# #通过sheet_by_index()获取的sheet没有write()方法
# rs = readOnlyBook.sheet_by_index(0)
#
# writableBook = copy(readOnlyBook)
#
# #通过get_sheet()获取的sheet有write()方法
# writableSheet = writableBook.get_sheet(0)
# writableSheet.write(0, 0, 'changed!')
#
# writableBook.save('E:\\123.xlsx')
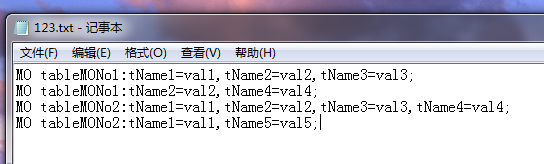
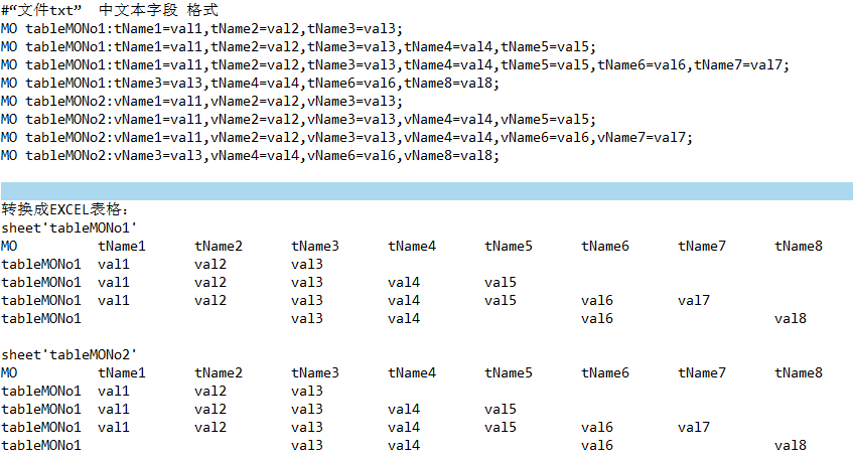
# testStr = "MO tableMONo1:tName1=val1,tName2=val2,tName3=val3;"
# print (testStr.find(" "))
# #find MO(要用)
# print (testStr[0 : testStr.find(" ")])
# #find tableMONo1(要用)
# print (testStr[testStr.find(" ")+1 : testStr.find(":")])
# #find tName1=val1,tName2=val2,tName3=val3
# print (testStr[testStr.find(":")+1 : testStr.find(";")])
# #分割字符串成数组tName1=val1和tName2=val2
# for childStr in testStr[testStr.find(":")+1 : testStr.find(";")].split(','):
# print(childStr)
# #继续分割数组成为tName1和val1(要用)
# for childStr in testStr[testStr.find(":")+1 : testStr.find(";")].split(','):
# print(childStr.split("=")[0])
# print(childStr.split("=")[1])
#从读取的一行中获取sheet的名字
def get_sheet_name_from_line(line):
return line[line.find(" ")+1 : line.find(":")]
def get_mo(line):
return line[0 : line.find(" ")]
def get_writable_excel():
return xlwt.Workbook()
def is_contains_sheet_name(excel_data, sheet_name):
for item in excel_data:
if item["sheet_name"] == sheet_name:
return True
return False
def add_sheet_name(excel_data, sheet_name):
excel_data.append({"sheet_name": sheet_name, "data": []})
def add_title_array(excel_data, index):
excel_data[index]["data"].append([])
def get_all_title_from_line(line):
title_array = [get_mo(line)]
for item in line[line.find(":")+1 : line.find(";")].split(','):
title_array.append(item.split("=")[0])
return title_array
def add_title_if_not_exists(title_array_in_excel_data, title):
for item in title_array_in_excel_data:
if item == title:
return
title_array_in_excel_data.append(title)
def get_sheet_index_by_sheet_name(excel_data, sheet_name):
for sheet_index in range(len(excel_data)):
if excel_data[sheet_index]["sheet_name"] == sheet_name:
return sheet_index
#根据title—list的长度,预订好数据list的长度,填入空值
def add_empty_data_list(excel_data, sheet_index):
for index in range(len(excel_data[sheet_index]["data"][0])):
excel_data[sheet_index]["data"][-1].append("")
def get_all_key_value_by_line(line):
key_value_list = []
for item in line[line.find(":")+1 : line.find(";")].split(','):
key_value_list.append({"key": item.split("=")[0], "value": item.split("=")[1]})
return key_value_list
def get_index_x_of_the_key(excel_data, sheet_index, key_value):
key_list = excel_data[sheet_index]["data"][0]
for index in range(len(key_list)):
if key_list[index] == key_value["key"]:
return index
def insert_value_into_excel_data(excel_data, sheet_index, value, index_x, index_y):
excel_data[sheet_index]["data"][index_y][index_x] = value
excel_data = []
#从txt中读按行读取,把标题数据写进list里
with open("E:\\123.txt") as f:
line = f.readline()
while line:
#添加sheet_name,添加标题空数组
sheet_name = get_sheet_name_from_line(line)
if is_contains_sheet_name(excel_data, sheet_name) == False:
add_sheet_name(excel_data, sheet_name)
add_title_array(excel_data, len(excel_data)-1)
#添加标题数据
for item in get_all_title_from_line(line):
add_title_if_not_exists(excel_data[len(excel_data)-1]["data"][0], item)
line = f.readline()
#再读一遍,把数据写进list里
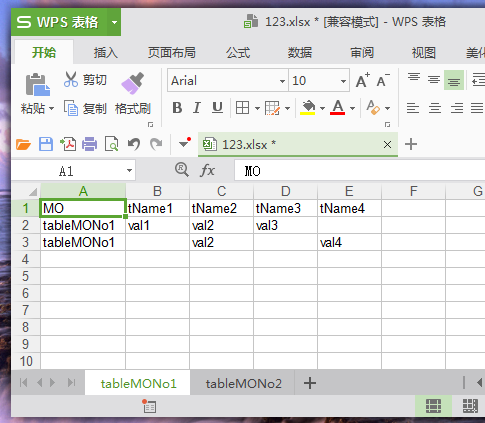
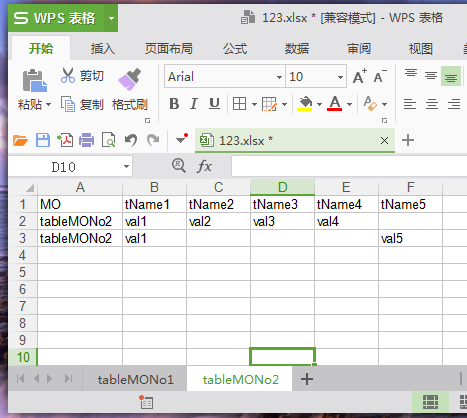
line_index = 0
with open("E:\\123.txt") as f:
line = f.readline()
while line:
sheet_name = get_sheet_name_from_line(line)
sheet_index = get_sheet_index_by_sheet_name(excel_data, sheet_name)
#添加一行
excel_data[sheet_index]["data"].append([])
#添加数据 -- 先填充空数据到列表中,再修改成需要的数据
add_empty_data_list(excel_data, sheet_index)
#先添加MO
excel_data[sheet_index]["data"][-1][0] = sheet_name
#然后添加数据
for key_value in get_all_key_value_by_line(line):
index_x = get_index_x_of_the_key(excel_data, sheet_index, key_value)
insert_value_into_excel_data(excel_data, sheet_index, key_value["value"], index_x, -1)
line = f.readline()
line_index = line_index + 1
#将excel_data写入excel
writable_excel = get_writable_excel()
for item_in_excel_data in excel_data:
writable_sheet = writable_excel.add_sheet(item_in_excel_data["sheet_name"], cell_overwrite_ok=True)
data_array = item_in_excel_data["data"]
for y in range(len(data_array)):
for x in range(len(data_array[y])):
writable_sheet.write(y, x, data_array[y][x])
writable_excel.save("E:\\123.xlsx")