


37,721
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享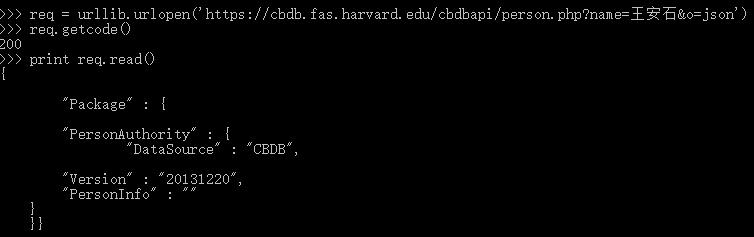

#!/usr/bin/env python
# -*- coding:utf-8 -*-
import urllib2
import urllib
import json
word = {
'name':'王安石',
'o':'json'
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
word = urllib.urlencode(word)
url = 'https://cbdb.fas.harvard.edu/cbdbapi/person.php?' + word
request = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(request)
data = json.loads(response.read())
data = json.dumps(data,ensure_ascii=False)
# f = open('3.json','w')
# f.write(data.encode('utf-8'))
print(data.encode('gbk'))




