



22,210
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

--测试数据
if not object_id(N'Tempdb..#T') is null
drop table #T
Go
Create table #T([VariableCode] int,[VariableName] nvarchar(24),[PVariableCode] INT,[VariableFullName] NVARCHAR(100))
Insert #T
select 1,N'根目录',0,'A' union all
select 2,N'第一级1',1,'A' union all
select 3,N'第一级2',1,'A' union all
select 4,N'第二级',3,'A' union all
select 5,N'B根目录',0,'B'
Go
--测试数据结束
DECLARE @sql VARCHAR(MAX)
SET @sql = '
;WITH cte AS (
Select *,1 AS rn from #T WHERE PVariableCode=0
UNION ALL
SELECT #T.*,cte.rn+1 FROM #T JOIN cte ON #T.PVariableCode=cte.VariableCode
)
select VariableFullName'
;WITH cte AS (
Select *,ROW_NUMBER()OVER(PARTITION BY VariableFullName ORDER BY PVariableCode) AS rn from #T WHERE PVariableCode=0
UNION ALL
SELECT #T.*,cte.rn+1 FROM #T JOIN cte ON #T.PVariableCode=cte.VariableCode
)
SELECT @sql = @sql + ',max(case rn when ' + RTRIM(rn)
+ ' then VariableName else '''' end)[第' + RTRIM(rn) + '级]'
FROM ( SELECT DISTINCT
rn
FROM cte
) a
SET @sql = @sql
+ ' from cte group by VariableFullName'
EXEC(@sql)
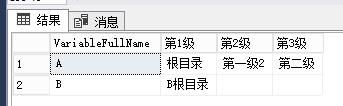
select * from SCS_Test a left join SCS_Test b on a.PVariableCode = b.VariableCode
and a.VariableLevel=4 and b.VariableLevel=3 select * from SCS_Test a left join SCS_Test b on a.PVariableCode = b.VariableCode
and a.VariableLevel=4 and b.VariableLevel=3 
VariableId VariableCode VariableName PVariableCode PVariableName VariableFullName
1 100 因变量 0 NULL NULL
2 100100 统计局口径 100 NULL NULL
3 100100100 汽油表观消费量 100100 NULL ytq
4 101 车辆变量 0 NULL NULL
5 101100 汽油车 101 NULL NULL
6 101100100 保有量 101100 NULL NULL
7 101100100100 标准车 101100100 NULL cqb0


