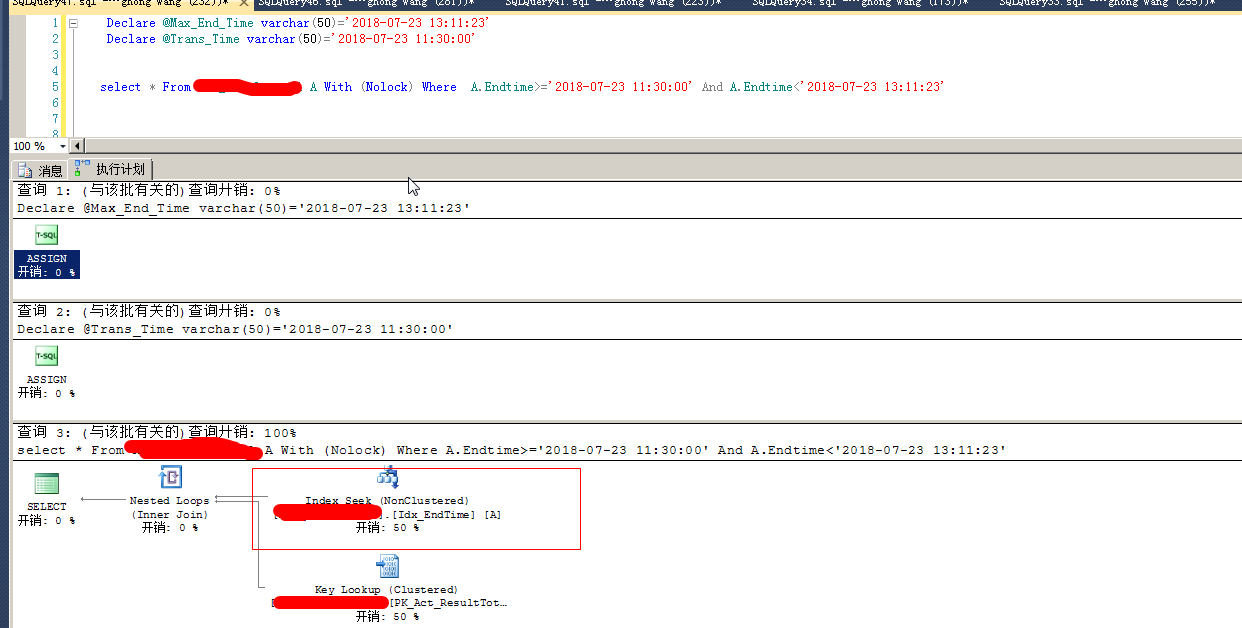
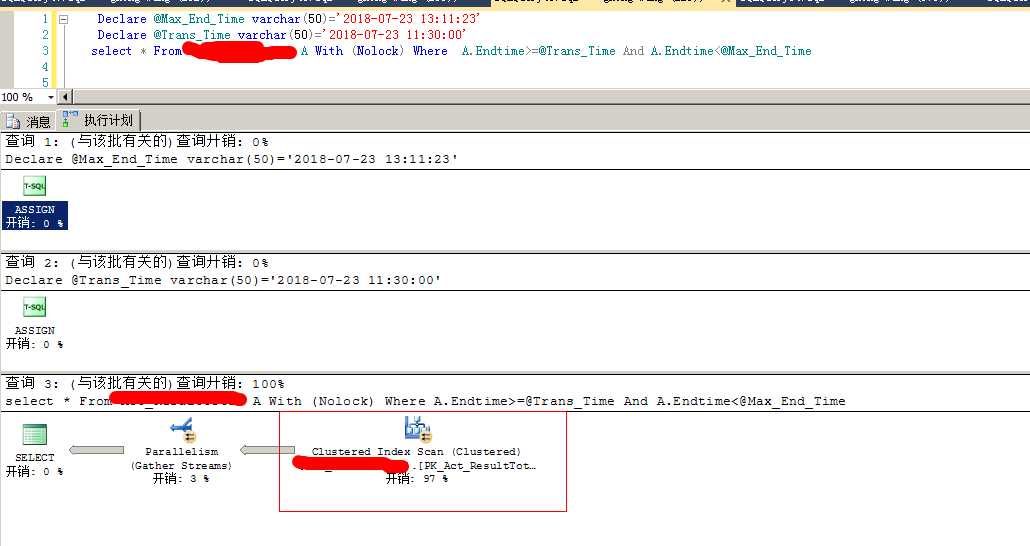
select * from t as A with(nolock) where a.endtime>=@t1 and a.endtime<@t2 option(recompile);
11,847
社区成员
33,668
社区内容
加载中
试试用AI创作助手写篇文章吧




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


