




56,677
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享 头秃。
头秃。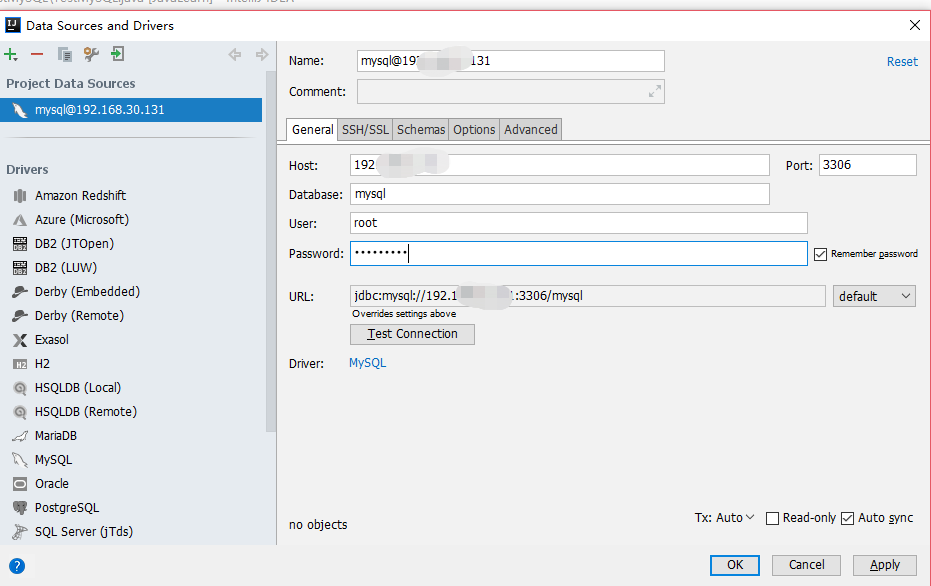
package TestMySQL;
import java.sql.*;
public class TestMySQL {
// JDBC 驱动名及数据库 URL
static final String JDBC_DRIVER = "com.mysql.jdbc.Driver";
static final String DB_URL = "jdbc:mysql://IP地址:3306/mysql";//ip地址不便透露,ip地址没有错
// 数据库的用户名与密码,需要根据自己的设置
static final String USER = "root";
static final String PASS = "密码";//密码不便透露
public static void main(String[] args) {
Connection conn = null;
Statement stmt = null;
try {
// 注册 JDBC 驱动
Class.forName("com.mysql.jdbc.Driver");
// 打开链接
System.out.println("连接数据库...");
conn = DriverManager.getConnection(DB_URL, USER, PASS);
// 执行查询
System.out.println(" 实例化Statement对象...");
stmt = conn.createStatement();
String sql;
sql = "SELECT id, name, url FROM websites";
ResultSet rs = stmt.executeQuery(sql);
// 展开结果集数据库
while (rs.next()) {
// 通过字段检索
int id = rs.getInt("id");
String name = rs.getString("name");
String url = rs.getString("url");
// 输出数据
System.out.print("ID: " + id);
System.out.print(", 站点名称: " + name);
System.out.print(", 站点 URL: " + url);
System.out.print("\n");
}
// 完成后关闭
rs.close();
stmt.close();
conn.close();
} catch (SQLException se) {
// 处理 JDBC 错误
se.printStackTrace();
} catch (Exception e) {
// 处理 Class.forName 错误
e.printStackTrace();
} finally {
// 关闭资源
try {
if (stmt != null) stmt.close();
} catch (SQLException se2) {
}// 什么都不做
try {
if (conn != null) conn.close();
} catch (SQLException se) {
se.printStackTrace();
}
}
System.out.println("Goodbye!");
}
}

