

22,296
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享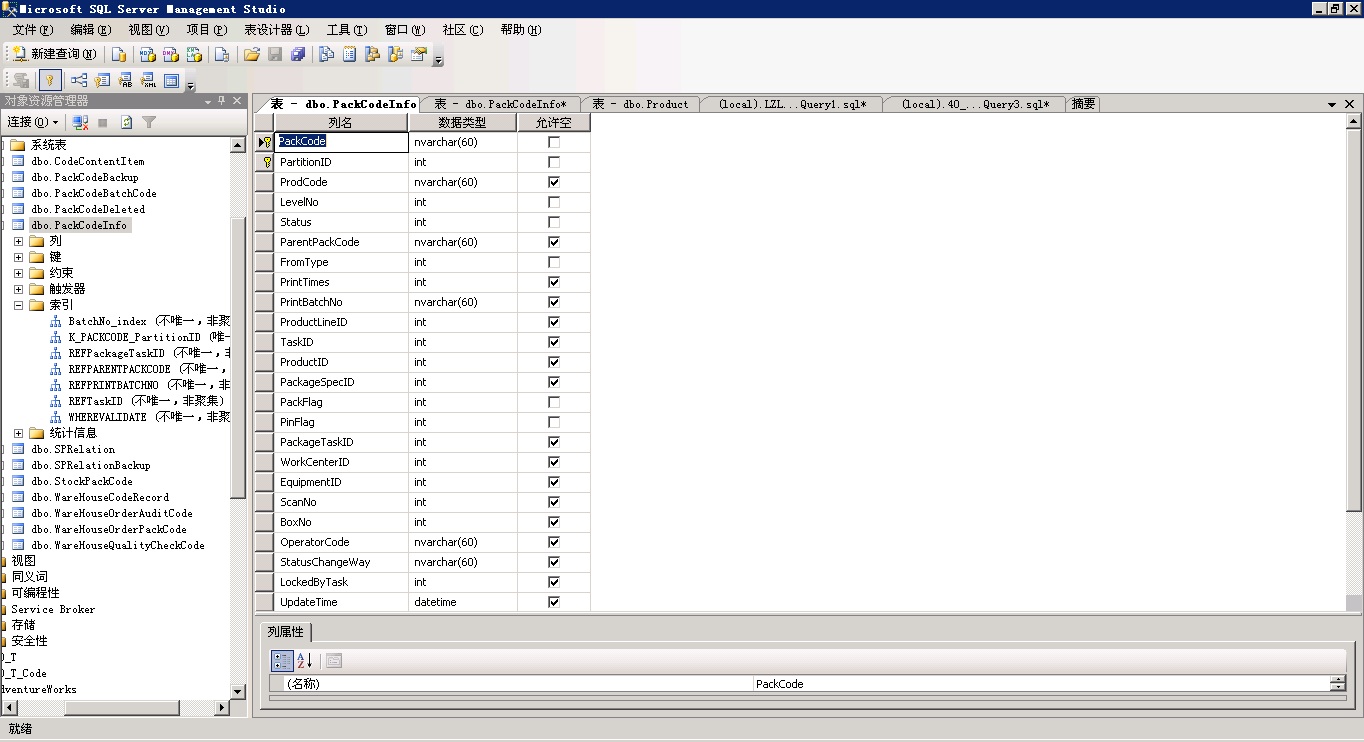





--1. 执行下这个, 贴出截图出来:
EXEC sp_helpindex 'PackCodeInfo'
--2. 这个的结果, 也贴截图出来
SELECT
COUNT(DISTINCT ProductID) AS ProductID_CNT
,COUNT(DISTINCT Batchno) AS Batchno_CNT
,COUNT(DISTINCT LevelNo) AS LevelNo_CNT
FROM PackCodeInfo WITH(NOLOCK)
--3. 分区不是空口白话,分区字段必须放在 where 之中才能提高效率
-- 3.1 你的 where 为什么不带分区字段?是否可以加上?
-- 3.2 你经常用的查询就是下面这个?
/*
select PackCode,BoxNo
from PackCodeInfo where ProductID='3' and Batchno='1305131' and LevelNo=2
order by Boxno
*/
--4. 这个表的增、删、改是否频繁?
--5. 所有不包含中文的字符串类字段, 都应该由 nvarchar 改为 varchar
--6. 2 亿多条数据, 已经是一个比较大的数据量, 想很快反应其实是比较困难的。
-- 首先, 不需要的历史数据应该归档到历史表。
-- 按日期分 历史表(一年前),较常用表(一年内),当前表(一个月内) 比较好;
-- 如果分 3 个表了还是卡或者不想分, 那你就得把常用的结果, 以报表形式弄出来,
-- 每天凌晨统计出结果报表, 让用户查最终的报表, 而不是直接查源表。

