


3,491
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
with tab1 as (
select 1 tour_id, 26 team_id, 9 sec from dual union all
select 1 , 96 , 10 from dual union all
select 1 , 26 , 10 from dual union all
select 1 , 26 , 12 from dual union all
select 1 , 96 , 12 from dual union all
select 1 , 26 , 19 from dual union all
select 1 , 96 , 22 from dual union all
select 2 , 26 , 9 from dual union all
select 2 , 10 , 10 from dual
)
select *
from tab1 t1
model
dimension by(
dense_rank() over(order by t1.tour_id, sec) dr,
row_number() over(partition by t1.tour_id, sec order by team_id desc) rn)
measures(-1 ord, tour_id, team_id, sec)
rules automatic order(
ord[dr, rn] order by dr, rn = decode(team_id[cv(), cv()], team_id[cv() - 1, 1], 1, 2)
)
order by dr, ord, rn
;
with tab1 as (
select 1 tour_id, 26 team_id, 9 sec from dual union all
select 1 , 96 , 10 from dual union all
select 1 , 26 , 10 from dual union all
select 1 , 26 , 12 from dual union all
select 1 , 96 , 12 from dual union all
select 1 , 26 , 19 from dual union all
select 1 , 96 , 22 from dual union all
select 2 , 26 , 9 from dual union all
select 2 , 10 , 10 from dual
)
select *
from tab1 t1
model
dimension by(
dense_rank() over(order by t1.tour_id, sec) dr,
row_number() over(partition by t1.tour_id, sec order by team_id desc) rn)
measures(-1 ord, tour_id, team_id, sec)
rules automatic order(
ord[dr, rn] order by dr, rn = decode(team_id[cv(), cv()], team_id[cv() - 1, 1], 1, 2)
)
order by dr, ord, rn
;with tab1 as (
select 1 tour_id, 26 team_id, 9 sec from dual union all
select 1 , 96 , 10 from dual union all
select 1 , 26 , 10 from dual union all
select 1 , 26 , 12 from dual union all
select 1 , 96 , 12 from dual union all
select 1 , 26 , 19 from dual union all
select 1 , 96 , 22 from dual union all
select 2 , 26 , 9 from dual union all
select 2 , 10 , 10 from dual
)
select *
from tab1 t1
model
dimension by(
dense_rank() over(order by t1.tour_id, sec) dr,
row_number() over(partition by t1.tour_id, sec order by team_id desc) rn)
measures(-1 ord, tour_id, team_id, sec)
rules automatic order(
ord[dr, rn] order by dr, rn = decode(team_id[cv(), cv()], team_id[cv() - 1, 1], 1, 2)
)
order by dr, ord, rn
;with tab1 as (
select 1 tour_id, 13 team_id, 9 sec from dual union all
select 1 , 26 , 9 from dual union all
select 1 , 96 , 10 from dual union all
select 1 , 26 , 10 from dual union all
select 1 , 26 , 12 from dual union all
select 1 , 96 , 12 from dual union all
select 1 , 13 , 19 from dual union all
select 1 , 26 , 19 from dual union all
--select 1 , 96 , 20 from dual union all
select 1 , 133 , 22 from dual union all
select 1 , 96 , 22 from dual union all
select 2 , 26 , 9 from dual union all
select 2 , 10 , 10 from dual
)
select *
from tab1 t1
model
dimension by(
dense_rank() over(order by t1.tour_id, sec) dr,
row_number() over(partition by t1.tour_id, sec order by team_id ) rn)
measures(-1 ord, tour_id, team_id, sec)
rules automatic order(
--ord[dr, rn] order by dr, rn = decode(team_id[cv(), cv()], team_id[cv() - 1, 1], 1, 2)
ord[dr, rn] order by dr, rn =
case when team_id[cv(), cv()] = max(decode(ord, 1, -99999999, team_id))[cv() - 1, rn]
then 1 else 2 end
)
order by dr, ord, rn
;

USE tempdb
GO
IF OBJECT_ID('t') IS NOT NULL DROP TABLE t
GO
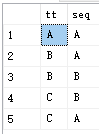
CREATE TABLE t(
tt VARCHAR(10),
seq VARCHAR(10)
)
GO
INSERT INTO t VALUES ('A','A')
INSERT INTO t VALUES ('B','B')
INSERT INTO t VALUES ('B','A')
INSERT INTO t VALUES ('C','A')
INSERT INTO t VALUES ('C','B')
---------- 以上为测试表及测试数据 ----------------
;WITH cte AS (
SELECT ROW_NUMBER() OVER (ORDER BY tt) AS rid,tt FROM t GROUP BY tt
),cte2 AS (
SELECT a.*,b.tt AS upTT FROM cte AS a LEFT JOIN cte AS b ON a.rid=b.rid+1
)
SELECT *
FROM t
ORDER BY
tt
,CASE WHEN EXISTS(
SELECT 1 FROM cte2 WHERE cte2.tt=t.tt AND cte2.upTT=t.seq
) THEN 0 ELSE 1 END,seq
with tab1 as (
select 'A' a, 'A' b from dual union all
select 'B' a, 'B' b from dual union all
select 'B' a, 'A' b from dual union all
select 'C' a, 'A' b from dual union all
select 'C' a, 'B' b from dual
)
, tab2 as (
select a, b, dense_rank() over(order by a) dr from tab1)
select a, b
from tab2
order by a, decode(b, first_value(a) over(order by dr range between 1 preceding and 0 following), 1, 2), b
;