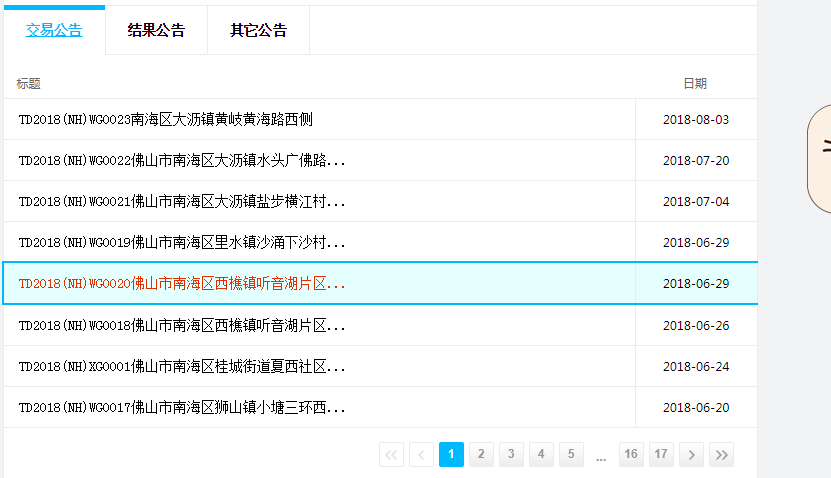
关于C#爬虫,想问一下,怎么抓指定table下面的内容
 筱玖 2018-08-07 10:15:29
筱玖 2018-08-07 10:15:29
<BODY style="ZOOM: 1">
<!-- 头部导航—开始 -->
<DIV class=publicheader>
<DIV class=secondtop>
<UL>
<LI class="f_l seclogo"><A href="/cms/html/nanhai/index.html"><!-- <img src="/cms/sites/nanhai/images/seclogo.png"> -->
<DIV id=seclogo><IMG src="/cms/sites/nanhai/images/d_logo_2.png"> <IMG src="/cms/sites/nanhai/images/d_logo_1.png"> </DIV></A></LI>
<LI class="f_r secsearch">
<DIV style="COLOR: #fff" class=pageheadernav><A href="/cms/html/nanhai/index.html">首页</A>|<A href="http://wza.nanhai.gov.cn" target=_blank>无障碍版</A>|<A href="javascript:getHerf(1)">移动版</A>|<A href="/cms/sites/nanhai/rss.jsp">RSS订阅</A>|<A href="javascript:getHerf(3)">简</A>|<A href="javascript:getHerf(4)">繁</A>|<A href="javascript:getHerf(5)">英</A> <A href="http://www.foshan.gov.cn" target=_blank><IMG src="/cms/sites/nanhai/images/foshan_logo.png"></A> </DIV>
<DIV id=searchDiv class=topsearch>
<FORM id=form1 method=post action=/cms/sites/nanhai/search_list.jsp target=_blank><INPUT id=area name=area value=3 type=hidden> <INPUT name=pos value=1 type=hidden> <INPUT name=appid value=1 type=hidden> <INPUT name=webid value=nanhai type=hidden> <INPUT id=col name=col type=hidden>
<DIV id=sobg_div_20140423>
<DIV class=toparrow>
<DIV onmouseover=funcSetOn(this,1) onmouseout=funcSetOn(this,0) onclick=funcSel(this) state="0"><INPUT id=quanbu class=tops_bans readOnly value=全部>
<UL style="DISPLAY: none; HEIGHT: 54px" class=topxiala>
<LI column="">全部
<LI column="8212">办事
<LI column="7975">服务 </LI></UL></DIV></DIV>
<DIV class=topsout_wen><INPUT id=my_q class=toptxtinput onkeypress=javascript:formSubmit(event) onclick="document.getElementById('sou_font').style.display='block';" name=q defaultval="您想找什么"> </DIV></DIV>
<DIV style="CURSOR: pointer" class=topgo onclick=doFormSubmit();></DIV>
<DIV style="DISPLAY: none" id=sou_font class=sou_font><STRONG>热词:</STRONG> <A style="CURSOR: pointer" class=red onclick="wordSubmit('国土');">国土</A> <A style="CURSOR: pointer" class=red onclick="wordSubmit('改造');">改造</A> <A style="CURSOR: pointer" class=red onclick="wordSubmit('水');">水</A> <A style="CURSOR: pointer" class=red onclick="wordSubmit('科技信息');">科技信息</A> <A style="CURSOR: pointer" class=red onclick="wordSubmit('测');">测</A> </DIV></FORM></DIV></LI></UL>
<DIV class=seccondmenu>
<DIV class=navbox jQuery16406240316072814886="1">
<P><A href="/cms/html/11146/column_11146_1.html"><IMG style="POSITION: relative; BOTTOM: 0px" src="/cms/sites/nanhai/images/index_icon_46.png"></A></P></DIV>
<DIV class=navbox jQuery16406240316072814886="2">
<P><A href="/cms/html/7855/column_7855_1.html"><IMG style="POSITION: relative; BOTTOM: 0px" src="/cms/sites/nanhai/images/index_icon_33.png"></A></P></DIV>
<DIV class=navbox jQuery16406240316072814886="3">
<P><A href="/cms/html/7849/column_7849_1.html"><IMG style="POSITION: relative; BOTTOM: 0px" src="/cms/sites/nanhai/images/index_icon_35.png"></A></P></DIV>
<DIV class=navbox jQuery16406240316072814886="4">
<P><A href="/cms/html/7850/column_7850_1.html"><IMG style="POSITION: relative; BOTTOM: 0px" src="/cms/sites/nanhai/images/index_icon_37.png"></A></P></DIV>
<DIV class=navbox jQuery16406240316072814886="5">
<P><A href="/cms/html/7851/column_7851_1.html"><IMG style="POSITION: relative; BOTTOM: 0px" src="/cms/sites/nanhai/images/index_icon_39.png"></A></P></DIV>
<DIV class=navbox jQuery16406240316072814886="6">
<P><A href="/cms/html/7852/column_7852_1.html"><IMG src="/cms/sites/nanhai/images/index_icon_41.png"></A></P></DIV>
<DIV class=navbox jQuery16406240316072814886="7">
<P><A href="http://data.nanhai.gov.cn" target=_blank><IMG src="/cms/sites/nanhai/images/index_icon_42.png"></A></P></DIV>
<DIV class=navbox jQuery16406240316072814886="8">
<P><A href="/cms/html/7854/column_7854_1.html"><IMG src="/cms/sites/nanhai/images/index_icon_43.png"></A></P></DIV></DIV></DIV></DIV>
<DIV style="POSITION: relative; HEIGHT: 63px" id=topbg class=topbg jQuery16406240316072814886="9">
<DIV class=top>
<DIV class=top_menu>
<DIV class=infor_title_z>
<DIV class=index_nav_list>
<UL>
<LI>
<DIV class=jr_menu>
<UL>
<LI id=one8 onmouseover="setTab('one',8,8)"><A href="http://www.nhggzy.cn/cms/html/11146/column_11146_1.html">今日南海</A></LI></UL></DIV></LI>
<LI>
<DIV class=dw_menu>
<UL>
<LI id=one6 onmouseover="setTab('one',6,8)"><A href="http://www.nhggzy.cn/cms/html/7855/column_7855_1.html">党务信息</A></LI></UL></DIV></LI>
<LI>
<DIV class=zw_menu>
<UL>
<LI id=one2 onmouseover="setTab('one',2,8)"><A href="http://www.nhggzy.cn/cms/html/7849/column_7849_1.html">政务公开</A></LI></UL></DIV></LI>
<LI>
<DIV class=hw_menu>
<UL>
<LI id=one3 onmouseover="setTab('one',3,8)"><A href="http://www.nhggzy.cn/cms/html/7850/column_7850_1.html">服务领域</A></LI></UL></DIV></LI>
<LI>
<DIV class=hd_menu>
<UL>
<LI id=one4 onmouseover="setTab('one',4,8)"><A href="http://www.nhggzy.cn/cms/html/7851/column_7851_1.html">互动交流</A></LI></UL></DIV></LI>
<LI>
<DIV class=rw_menu>
<UL>
<LI id=one5 onmouseover="setTab('one',5,8)"><A href="http://www.nhggzy.cn/cms/html/7852/column_7852_1.html">人文南海</A></LI></UL></DIV></LI>
<LI>
<DIV class=ss_menu>
<UL>
<LI id=one1 onmouseover="setTab('one',1,8)"><A href="http://data.nanhai.gov.cn/" target=_blank>数说·南海</A></LI></UL></DIV></LI>
<LI>
<DIV class=bj_menu>
<UL>
<LI id=one7 class=hover onmouseover="setTab('one',7,8)"><A href="http://www.nhggzy.cn/cms/html/14272/column_14272_1.html">组织机构</A></LI></UL></DIV></LI></UL></DIV></DIV>
<DIV class=clean></DIV>
<DIV class=infor_textc>
<DIV style="DISPLAY: none" id=con_one_1>
<DIV class=ss_nhai_menu>
<UL>
<LI><A class=menu_c href="http://data.nanhai.cn/cms/sites/sjzy/folder.jsp" target=_blank>数据目录</A> | </LI>
<LI><A class=menu_c href="http://data.nanhai.cn/cms/sites/sjzy/list_app.jsp?ColumnID=11452" target=_blank>数据应用</A> | </LI>
<LI><A class=menu_c href="http://data.nanhai.cn/cms/sites/sjzy/list_alone.jsp?ColumnID=11454" target=_blank>互动交流</A> | </LI>
<LI><A class=menu_c href="http://data.nanhai.cn/cms/sites/sjzy/list_alone.jsp?ColumnID=11460" target=_blank>关于我们</A></LI></UL></DIV></DIV>
<DIV style="DISPLAY: none" id=con_one_8>
<DIV class=jr_nhai_menu>
<UL>
<LI><A class=menu_c href="http://www.nhggzy.cn/cms/html/11147/column_11147_1.html">时政经济</A> | </LI>
<LI><A class=menu_c href="http://www.nhggzy.cn/cms/html/11148/column_11148_1.html">社会新闻</A> | </LI>
<LI><A class=menu_c href="http://www.nhggzy.cn/cms/html/11149/column_11149_1.html">镇街新闻</A> | </LI>
<LI><A class=menu_c href="http://www.nhggzy.cn/cms/html/11150/column_11150_1.html">社区新闻</A> | </LI>
<LI><A class=menu_c href="http://www.nhggzy.cn/cms/html/11151/column_11151_1.html">特别关注</A> | </LI>
<LI><A class=menu_c href="http://www.nhggzy.cn/cms/html/11152/column_11152_1.html">城事民生</A> | </LI>
<LI><A class=menu_c href="http://www.nhggzy.cn/cms/html/11153/column_11153_1.html">梁心帮办</A> | </LI>
<LI><A class=menu_c href="http://www.nhggzy.cn/cms/html/11154/column_11154_1.html">南海乡音</A> | </LI>
<LI><A class=menu_c href="http://www.nhggzy.cn/cms/html/11155/column_11155_1.html">有为对话</A> | </LI>
<LI><A class=menu_c href="http://www.nhggzy.cn/cms/html/11156/column_11156_1.html">市民议事厅</A> | </LI>
<LI><A class=menu_c href="http://www.nhggzy.cn/cms/html/11157/column_11157_1.html">南海观察</A></LI></UL></DIV></DIV>
<DIV style="DISPLAY: none" id=con_one_6>
<DIV class=zi_dw_menu>
<UL>
<LI><A class=menu_c href="http://www.nhggzy.cn/cms/html/7860/column_7860_1.html">党务动态</A> | </LI>
<LI><A class=menu_c href="http://www.nhggzy.cn/cms/html/7861/column_7861_1.html">通知公告</A> | </LI>
<LI><A class=menu_c href="http://www.nhggzy.cn/cms/html/7962/column_7962_1.html">党委文件</A> | </LI>
<LI><A class=menu_c href="http://www.nhggzy.cn/cms/html/7964/column_7964_1.html">区


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享






 没用过Nuget吗?
没用过Nuget吗?