37,738
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
patten=r'<tr>(.*?)</tr>'
regex=re.compile(patten)
text=regex.findall(content,re.S|re.M)

import re
content = '''
<tr>
<td align="center" name="sn" >2018001</td>
<td align="center" name="name" >张三</td>
<td align="center" name="gender" >女</td>
<td align="center" name="age" >20</td>
<td align="center" name="nation" >汉族</td>
<td align="center" name="score" >560</td>
</tr>
<tr>
<td align="center" name="sn" >2018002</td>
<td align="center" name="name" >李四</td>
<td align="center" name="gender" >男</td>
<td align="center" name="age" >21</td>
<td align="center" name="nation" >维吾尔族</td>
<td align="center" name="score" >600</td>
</tr>
<tr>
<td align="center" name="sn" >2018003</td>
<td align="center" name="name" >王麻子</td>
<td align="center" name="gender" >男</td>
<td align="center" name="age" >23</td>
<td align="center" name="nation" >回族</td>
<td align="center" name="score" >669</td>
</tr>
<tr>
<td align="center" name="sn" >2018004</td>
<td align="center" name="name" >李雷</td>
<td align="center" name="gender" >男</td>
<td align="center" name="age" >20</td>
<td align="center" name="nation" >汉族</td>
<td align="center" name="score" >580</td>
</tr>
'''
patten = r'<tr>(.*?)</tr>'
regex = re.compile(patten, re.S)
text = regex.findall(content)
for tr in text:
print('-----------------------------------------------')
print(tr)

patten=r'<tr>(.*?)</tr>'
regex=re.compile(patten)
text=regex.findall(content,re.S|re.M)
patten=r'<tr>(.*?)</tr>'
regex=re.compile(patten,re.S|re.M)
text=regex.findall(content)

import re
com = re.compile(r'<tr>(.*?)</tr>', re.S)
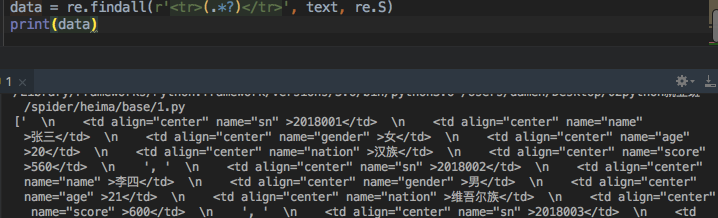
data = re.findall(com, text)
print(data)
data=re.findall(r'<tr>(.*?)</tr>',content,re.S)
patten=r'<tr>(.*?)</tr>'
regex=re.compile(patten)
data=regex.findall(content,re.S)