


37,741
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
def check_value(dt):
d_flag = 0
for i in range(1,6):
d1 = 1 if ( abs(dt['d'+str(i)] - dt['d'+str(i+1)]) == 1 ) else 0
d_flag = d_flag + d1
return d_flag
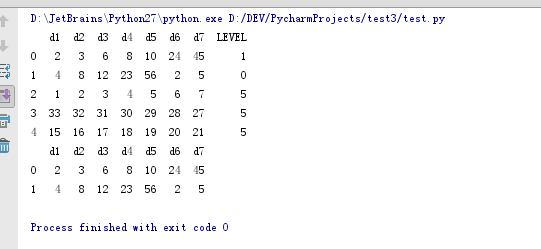
data_cols = ['d1', 'd2', 'd3', 'd4', 'd5', 'd6', 'd7']
data_txt = pd.read_csv(r'd:\demo\test1.txt', names = data_cols)
data_txt['LEVEL'] = data_txt.apply(lambda x: check_value(x),axis=1)
df1 = data_txt[data_txt['LEVEL']<4]
print df1[data_cols]



import re
pattern=r'.*?([0-9]{1,3}).*?'
regex=re.compile(pattern,re.S)
filename=r'c:\tn.txt'
l,ll=[],[]
with open(filename,'r',encoding="utf-8") as fobj:
lines=fobj.readlines()
with open(filename, 'w',encoding="utf-8") as f_w:
for line in lines:
#用正则表达式把每行的内容读入列表
str=regex.findall(line)
for i in range(len(str)):
# 将列表的元素转为int,存入新列表
l.append(int(str[i]))
# 构建新列表ll,以l的第一个元素作为第一个元素,其他元素递增
ll=[l[0]+i for i in range(0,len(l))]
# 判断l和ll是否相同
if l==ll :
# 相同设置line为其他值
line='------\n'
# 把line写入文件
f_w.write(line)
l=[]
fobj.close()
f_w.close()

