KYLIN cube优化相关的
最近在研究 KYlin 优化的问题,想问个问题,
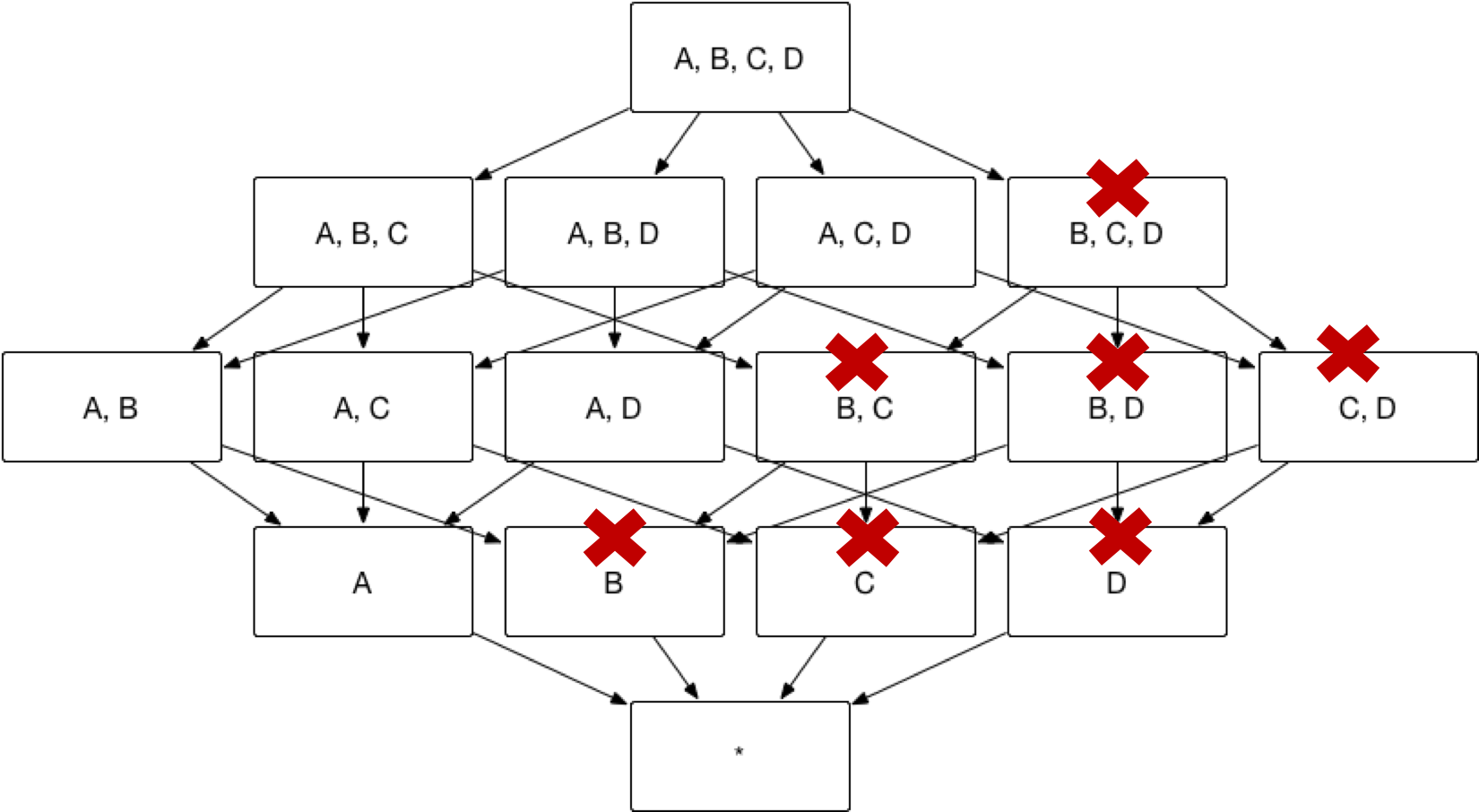
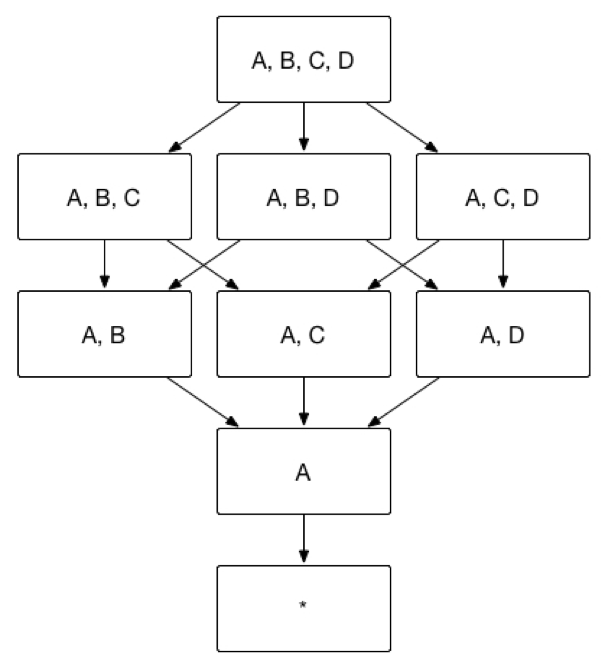
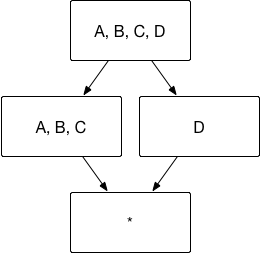
Kylin中建Cube时使用了Mandatory Dimensions,Joint Dimensions时,比如有维度A、B、C、D,E 我建的维度是 Mandatory Dimensions 为 A,B,
Joint Dimensions 为C,D,E,我查询的sql是
1, select C, count(C) from tableinfo where A=1 AND B= 2 group by c
2, select D, count(D) from tableinfo where A=1 AND B= 2 group by D
2, select E, count(E) from tableinfo where A=1 AND B= 2 group by E
这样能命中相应cuboid吗?或者有更好的推荐吗?(A,B一般都是写在where条件里,不放在group by后面)


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享