

22,296
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享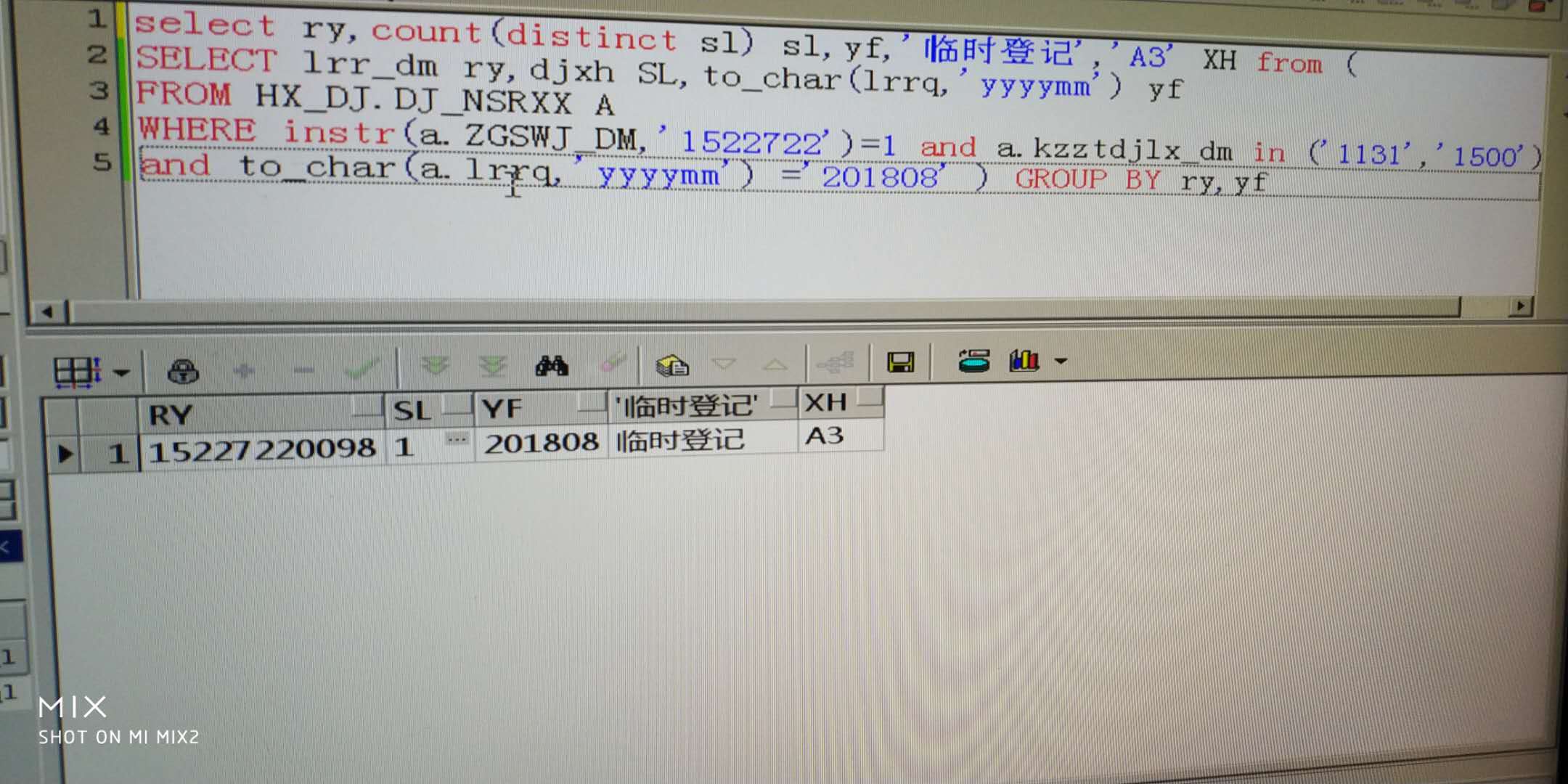

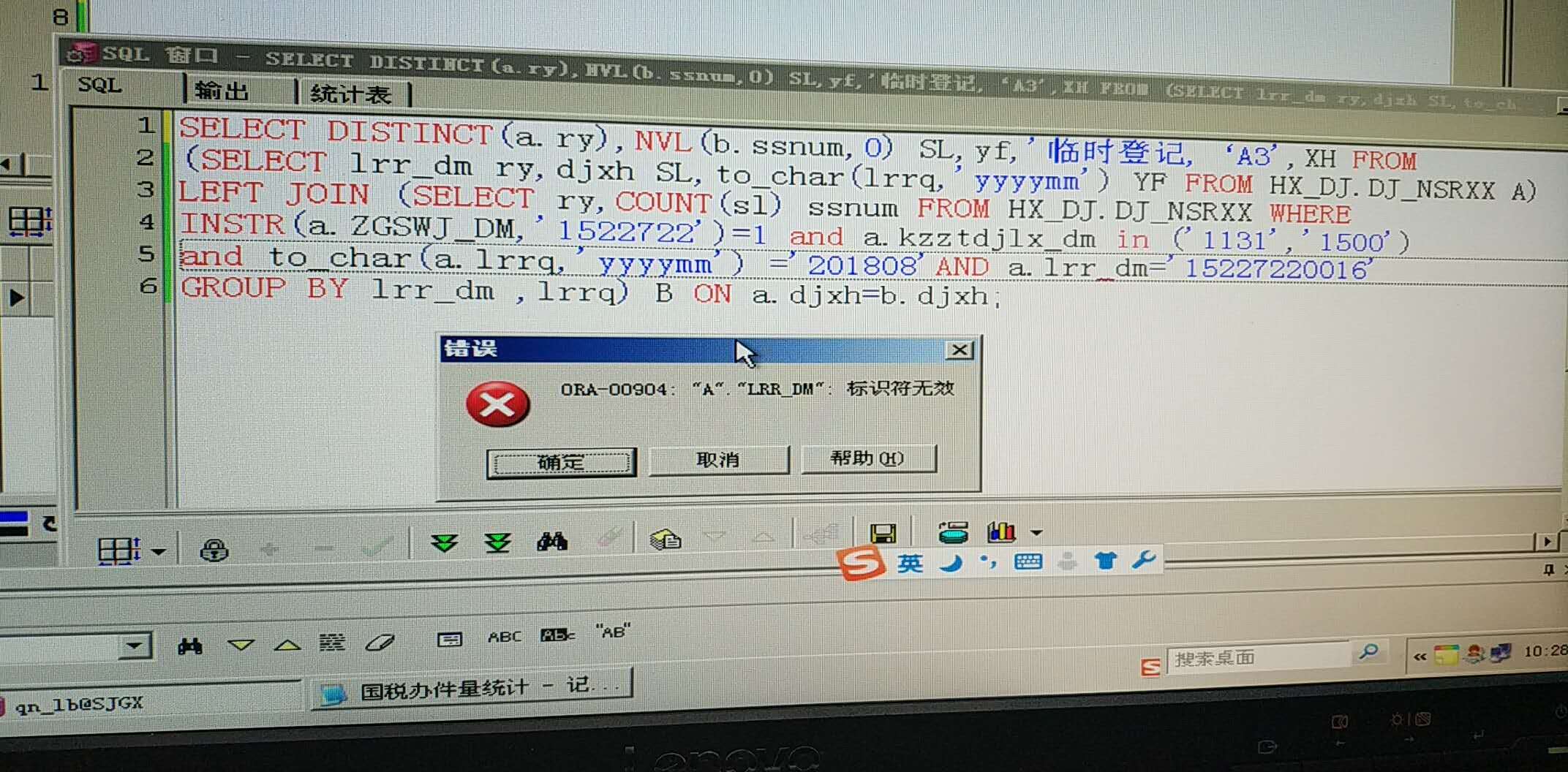 (这个临时登记少了一个单引号,我已经加上去了,也是一样的错误)[/quote]
(SELECT lrr_dm ry,djxh SL,to_char(lrrq,'yyyymm') yf FROM HX_DJ.DJ_NSRXX A) 这个衍生表后面还要加别名,也就是(SELECT lrr_dm ry,djxh SL,to_char(lrrq,'yyyymm') yf FROM HX_DJ.DJ_NSRXX A ) as A
还有,你第二个衍生表里面怎么没有 djxh
(这个临时登记少了一个单引号,我已经加上去了,也是一样的错误)[/quote]
(SELECT lrr_dm ry,djxh SL,to_char(lrrq,'yyyymm') yf FROM HX_DJ.DJ_NSRXX A) 这个衍生表后面还要加别名,也就是(SELECT lrr_dm ry,djxh SL,to_char(lrrq,'yyyymm') yf FROM HX_DJ.DJ_NSRXX A ) as A
还有,你第二个衍生表里面怎么没有 djxh

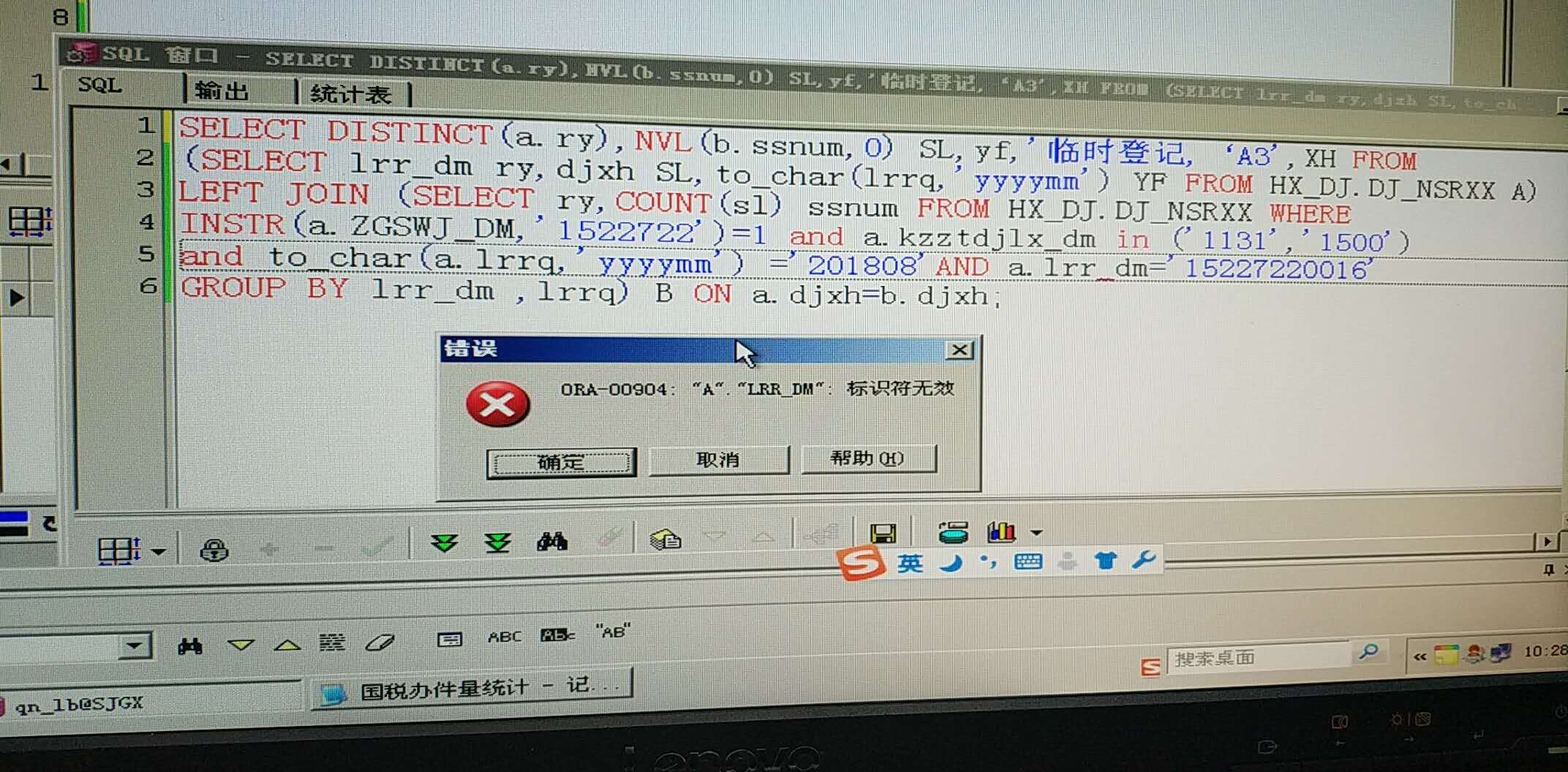
 (这个临时登记少了一个单引号,我已经加上去了,也是一样的错误)[/quote]
(SELECT lrr_dm ry,djxh SL,to_char(lrrq,'yyyymm') yf FROM HX_DJ.DJ_NSRXX A) 这个衍生表后面还要加别名,也就是(SELECT lrr_dm ry,djxh SL,to_char(lrrq,'yyyymm') yf FROM HX_DJ.DJ_NSRXX A ) as A
还有,你第二个衍生表里面怎么没有 djxh[/quote]
我加上去了。。。是这样吧(我基础比较差,但现在有这个任务,所以是一边查资料一边改的)
(这个临时登记少了一个单引号,我已经加上去了,也是一样的错误)[/quote]
(SELECT lrr_dm ry,djxh SL,to_char(lrrq,'yyyymm') yf FROM HX_DJ.DJ_NSRXX A) 这个衍生表后面还要加别名,也就是(SELECT lrr_dm ry,djxh SL,to_char(lrrq,'yyyymm') yf FROM HX_DJ.DJ_NSRXX A ) as A
还有,你第二个衍生表里面怎么没有 djxh[/quote]
我加上去了。。。是这样吧(我基础比较差,但现在有这个任务,所以是一边查资料一边改的)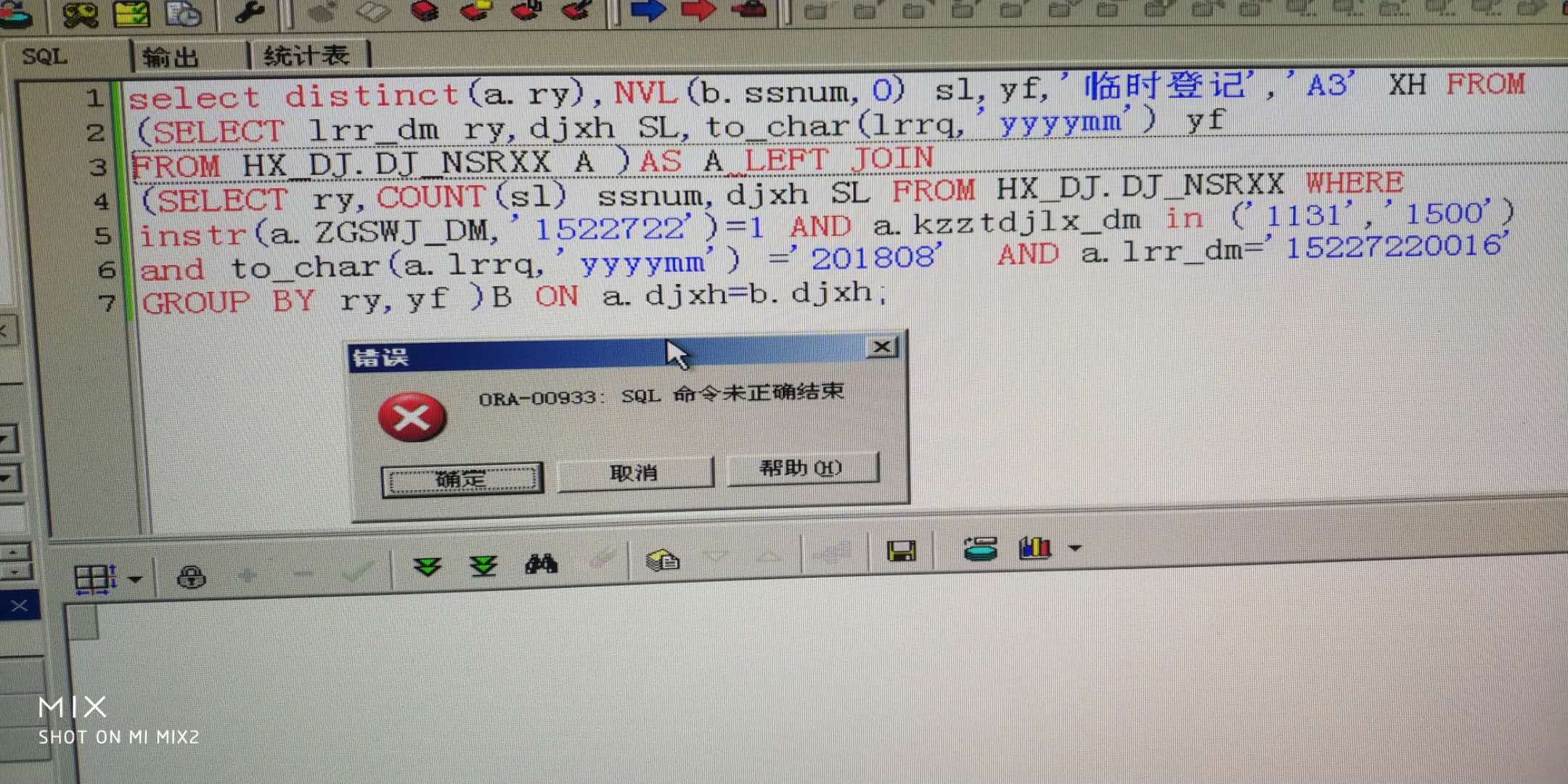 [/quote]
(SELECT lrr_dm ry,djxh SL,to_char(lrrq,'yyyymm') yf FROM HX_DJ.DJ_NSRXX A ) as A改成(SELECT lrr_dm ry,djxh SL,to_char(lrrq,'yyyymm') yf FROM HX_DJ.DJ_NSRXX A ) A,再试试
ORACLE不支持用AS来赋予表别名
[/quote]
(SELECT lrr_dm ry,djxh SL,to_char(lrrq,'yyyymm') yf FROM HX_DJ.DJ_NSRXX A ) as A改成(SELECT lrr_dm ry,djxh SL,to_char(lrrq,'yyyymm') yf FROM HX_DJ.DJ_NSRXX A ) A,再试试
ORACLE不支持用AS来赋予表别名
