社区
搜索引擎技术
帖子详情
solr 多值分词 查询问题
1????
2018-09-17 03:29:51
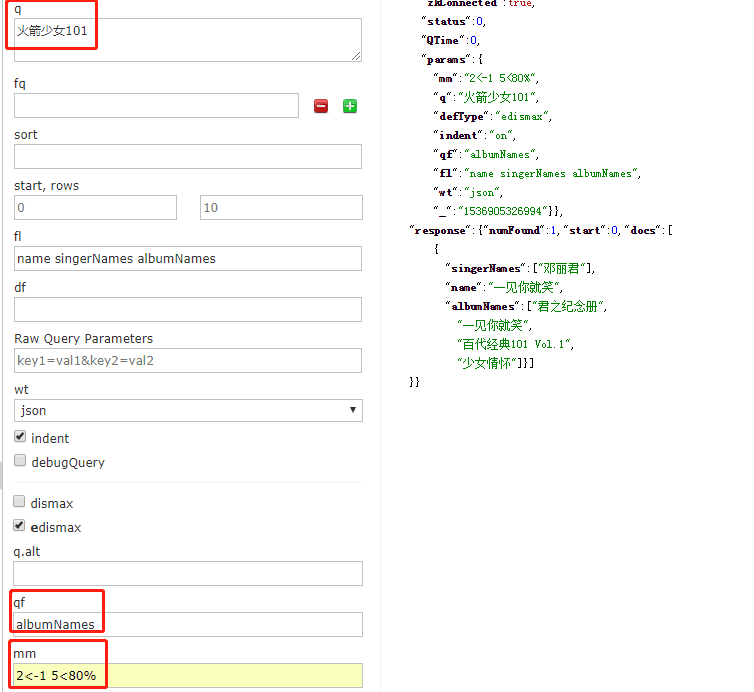
如图所示:搜出来的这个结果不尽如人意,匹配跨越了多值,不想被搜索出来,有什么办法解决呢?
...全文
203
回复
打赏
收藏
solr 多值分词 查询问题
如图所示:搜出来的这个结果不尽如人意,匹配跨越了多值,不想被搜索出来,有什么办法解决呢?
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
中文
分词
工具word-1.0,Java实现的中文
分词
组件多种基于词典的
分词
算法
word
分词
是一个Java实现的中文
分词
组件,提供了多种基于词典的
分词
算法,并利用ngram模型来消除歧义。 能准确识别英文、数字,以及日期、时间等数量词,能识别人名、地名、组织机构名等未登录词。 同时提供了Lucene、
Solr
、ElasticSearch插件。
分词
使用方法: 1、快速体验 运行项目根目录下的脚本demo-word.bat可以快速体验
分词
效果 用法: command [text] [input] [output] 命令command的可选值为:demo、text、file demo text 杨尚川是APDPlat应用级产品开发平台的作者 file d:/text.txt d:/word.txt exit 2、对文本进行
分词
移除停用词:List words = WordSegmenter.seg("杨尚川是APDPlat应用级产品开发平台的作者"); 保留停用词:List words = WordSegmenter.segWithStopWords("杨尚川是APDPlat应用级产品开发平台的作者"); System.out.println(words); 输出: 移除停用词:[杨尚川, apdplat, 应用级, 产品, 开发平台, 作者] 保留停用词:[杨尚川, 是, apdplat, 应用级, 产品, 开发平台, 的, 作者] 3、对文件进行
分词
String input = "d:/text.txt"; String output = "d:/word.txt"; 移除停用词:WordSegmenter.seg(new File(input), new File(output)); 保留停用词:WordSegmenter.segWithStopWords(new File(input), new File(output)); 4、自定义配置文件 默认配置文件为类路径下的word.conf,打包在word-x.x.jar中 自定义配置文件为类路径下的word.local.conf,需要用户自己提供 如果自定义配置和默认配置相同,自定义配置会覆盖默认配置 配置文件编码为UTF-8 5、自定义用户词库 自定义用户词库为一个或多个文件夹或文件,可以使用绝对路径或相对路径 用户词库由多个词典文件组成,文件编码为UTF-8 词典文件的格式为文本文件,一行代表一个词 可以通过系统属性或配置文件的方式来指定路径,多个路径之间用逗号分隔开 类路径下的词典文件,需要在相对路径前加入前缀classpath: 指定方式有三种: 指定方式一,编程指定(高优先级): WordConfTools.set("dic.path", "classpath:dic.txt,d:/custom_dic"); DictionaryFactory.reload();//更改词典路径之后,重新加载词典 指定方式二,Java虚拟机启动参数(中优先级): java -Ddic.path=classpath:dic.txt,d:/custom_dic 指定方式三,配置文件指定(低优先级): 使用类路径下的文件word.local.conf来指定配置信息 dic.path=classpath:dic.txt,d:/custom_dic 如未指定,则默认使用类路径下的dic.txt词典文件 6、自定义停用词词库 使用方式和自定义用户词库类似,配置项为: stopwords.path=classpath:stopwords.txt,d:/custom_stopwords_dic 7、自动检测词库变化 可以自动检测自定义用户词库和自定义停用词词库的变化 包含类路径下的文件和文件夹、非类路径下的绝对路径和相对路径 如: classpath:dic.txt,classpath:custom_dic_dir, d:/dic_more.txt,d:/DIC_DIR,D:/DIC2_DIR,my_dic_dir,my_dic_file.txt classpath:stopwords.txt,classpath:custom_stopwords_dic_dir, d:/stopwords_more.txt,d:/STOPWORDS_DIR,d:/STOPWORDS2_DIR,stopwords_dir,remove.txt 8、显式指定
分词
算法 对文本进行
分词
时,可显式指定特定的
分词
算法,如: WordSegmenter.seg("APDPlat应用级产品开发平台", SegmentationA
Solr
的基本使用
schema.xml,在
Solr
Core的conf目录下,它是
Solr
数据表配置文件,它定义了加入索引的数据的数据类型的。主要包括FieldTypes、Fields和其他的一些缺省设置。field:进行索引,需要创建document,document中包括了很多的field(域)。 field属性:是否索引、是否存储、是否
分词
,是否
多值
multiValuedmultiValued:该Field如果要存储多个值时设置为true,
solr
允许一个Field存储多个值,比如存储一个用户的好友id(多个),商品的图片(多个,大图和小图),通过使用
solr
查询
要看出返回给客户端是数组:Field
solr
java
查询
_java调用
solr
的
分词
查询
结果
一、修改
solr
-7.3.1\server\
solr
\articles【创建的core的名称】\conf\managed-schema文件1、增加中文的
分词
器:2、增加字段名,指定text_cn类型:3、pom引入jiarorg.springframework.dataspring-data-
solr
二、java代码如下:package com.silverbox.
solr
;import jav...
solr
中英文
分词
模糊
查询
在
solr
的
分词
配置后成功后,在
solr
后台管理界面进行模糊
查询
的时候会存在
分词
匹配个数的
问题
。打个简单的比方:搜索兰州XXXX酒店。 往往这个时候就有一大批数据出来,只要包含了
分词
后的词的数据都会搜索出来,给客户的体验不怎么好,本来客户是想只展示兰州的XXXX酒店的,结果北京的、广州的,还有其他名称的酒店都给搜索出来。这个时候就是
分词
的匹配个数设置的
问题
了。 首先还是看下
分词
的配置(IK ...
Solr
分词
搜索--
solr
j简单
查询
1.安装下载 下载路径:
solr
-7.5.0下载 2.安装配置 7.5的
solr
是自带jetty容器的,不需要通过tomcat,解压后通过cmd来启动,默认端口为8983
solr
启动、停止、重启命令
solr
start -p 端口号
solr
stop -all
solr
restart -p 端口号 启动成功,登录管理页http://127.0.0.1:8983/
solr
/#/ ...
搜索引擎技术
2,760
社区成员
2,052
社区内容
发帖
与我相关
我的任务
搜索引擎技术
搜索引擎的服务器通过网络搜索软件或网络登录等方式,将Internet上大量网站的页面信息收集到本地,经过加工处理建立信息数据库和索引数据库。
复制链接
扫一扫
分享
社区描述
搜索引擎的服务器通过网络搜索软件或网络登录等方式,将Internet上大量网站的页面信息收集到本地,经过加工处理建立信息数据库和索引数据库。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
