社区
Hadoop生态社区
帖子详情
为什么spark所有的计算都集中到了一台机器上,所有的executor都用了一台机器上的?
会飞的犬良
2018-10-11 06:53:12
spark计算的时候,机器不是一台,但是所有的计算都只用了一台机器上的资源,但是。但是数据源是多台的机器上的。!
这是什么问题,肯定是影响计算的,并且 Locality Level 都是any的,说明数据都转移到了这台机器上来计算了。哪位朋友走过路过,帮忙看下什么问题。
...全文
644
1
打赏
收藏
为什么spark所有的计算都集中到了一台机器上,所有的executor都用了一台机器上的?
spark计算的时候,机器不是一台,但是所有的计算都只用了一台机器上的资源,但是。但是数据源是多台的机器上的。!这是什么问题,肯定是影响计算的,并且Locality Level 都是any的,说明数据都转移到了这台机器上来计算了。哪位朋友走过路过,帮忙看下什么问题。
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
1 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
会飞的犬良
2018-10-16
打赏
举报
回复
问题已经解决了,通过查看work的错误日志发现,slave节点与主节点netty通信出现了异常,然后查看SPARK_CLASSPATH路径下的netty相关的jar包冲突了。去掉一个就好了。
spark
:
Exec
u
tor
分配详解
用户应用new
Spark
Context后,集群就会为在Worker上分配
exec
u
tor
,但是增加
exec
u
tor
的时候需要考虑好内存消耗,因为
一台
机器
的内存分配给越多的
exec
u
tor
,每个
exec
u
tor
的内存就越小,以致出现过多的数据spill over...
Spark
仅有一个节点上有
exec
u
tor
解决方案
使用jps查看进程,发现每一个节点
机器
上都有Workers,但是在使用standalone模式提交一个
spark
任务时,通过命令行中的logging information发现生成的
exec
u
tor
仅仅在一个节点
机器
的ip上。 上网搜索以后发现遇到类似...
Spark
3.0.0 Driver 启动内幕
本课程讲解
Spark
3.0.0 ...SchedulerBackend 解析:SchedulerBackend 原理剖析、SchedulerBackend 源码解析、
Spark
程序的注册机制、
Spark
程序对
计算
资源
Exec
u
tor
的管理; 打通
Spark
系统运行内幕机制循环流程。
Spark
中的Driver和
Exec
u
tor
的个人理解
Driver:Driver是
Spark
中Application也即代码的发布程序,可以理解为我们编写
spark
代码的主程序,因此只有一个,负责对
spark
中
Spark
Context对象进行创建,其中
Spark
Context对象负责创建
Spark
中的RDD(
Spark
中的基本...
spark
2.3程序如何在启动时指定
exec
u
tor
在固定的主机上运行
在
Spark
2.3中,您可以在启动时通过设置
spark
.
exec
u
tor
.instances 和
spark
.
exec
u
tor
.hostname 属性来指定执行器在固定的主机上运行。 具体来说,您可以使用以下命令启动
Spark
2.3应用程序: $
spark
-submit \ --...
Hadoop生态社区
20,808
社区成员
4,690
社区内容
发帖
与我相关
我的任务
Hadoop生态社区
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
复制链接
扫一扫
分享
社区描述
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享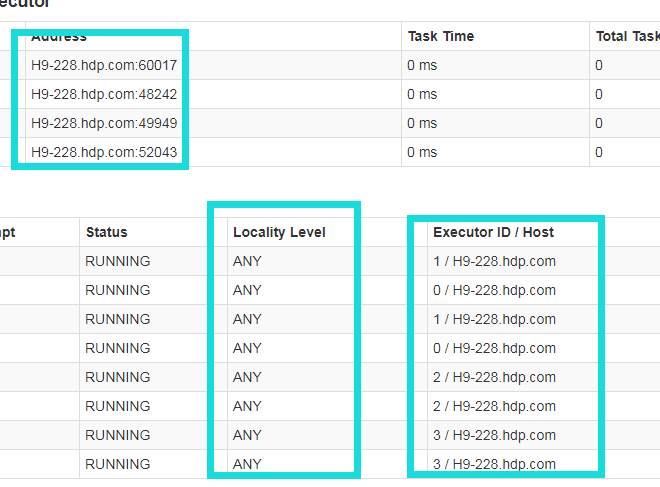 这是什么问题,肯定是影响计算的,并且 Locality Level 都是any的,说明数据都转移到了这台机器上来计算了。哪位朋友走过路过,帮忙看下什么问题。
这是什么问题,肯定是影响计算的,并且 Locality Level 都是any的,说明数据都转移到了这台机器上来计算了。哪位朋友走过路过,帮忙看下什么问题。

