scrapy xpath问题
自己做了个爬虫实验,
http://xzsp.cangzhou.gov.cn/HBSC/Services/zwfwzx/a_article.jsp?SiteID=96&aid=d6e389c3-9a3d-40f7-bedf-8f6265b2deb5
想爬出
中标供应商名称 中标供应商地址 中标金额(元) 统一社会信用代码
杭州求晟科技有限公司 浙江省杭州市上城区莫干山路1418-8号3幢(上城科技工业基地) 778,700.00 91330102MA2CC70W8R
<tr><td><table width="650" style="white-space:nowrap;"><tr border="1px" !important><td border="1px" !important colspan="5">包号:Z1309001819492001-2 <br>包名:嵌入式实验室、分布式过程控制实验室设备</td></tr><tr ><td ><table width="650" style="white-space:normal;" border="1" !important><tr ><td width="25%" align="center">中标供应商名称</td><td width="25%" align="center">中标供应商地址</td><td width="25%" align="center">中标金额(元)</td><td width="25%" align="center">统一社会信用代码</td></tr ></table></td ></tr><tr ><td ><table width="650" style="white-space:normal;" !important border="1" !important><tr><td width="25%" align="center" > 杭州求晟科技有限公司 </td><td width="25%" align="center"> 浙江省杭州市上城区莫干山路1418-8号3幢(上城科技工业基地) </td><td width="25%" align="center" > 778,700.00 </td><td width="25%" align="center">91330102MA2CC70W8R</td></tr ></table></td ></tr ><tr ><td ><table width="650" style="white-space:normal;" border="1" !important><tr ><td width="25%" align="center">主要标的名称</td><td width="25%" align="center">规格型号</td><td width="25%" align="center">单价(元)</td><td width="25%" align="center">数量</td></tr ></table></td ></tr ><tr ><td ><table width="650" style="white-space:normal;" border="1" !important><tr ><td width="25%" align="center">详见招标(采购)文件</td><td width="25%" align="center">详见招标(采购)文件</td><td width="25%" align="center">详见招标(响应)文件</td><td width="25%" align="center">详见招标(采购)文件</td></tr ></table></td ></tr ></tr></table></td>
def parse_article(self, response):
detail = response.xpath('//table')
item = ZhongbiaoxxItem()
item['ysje'] = detail.xpath('tr[17]/td/table/tr[1]/td/text()')[0].extract()
item['cgyt'] = detail.xpath('tr[17]/td/table/tr[2]/td/text()')[0].extract()
item['ssdd'] = detail.xpath('tr[17]/td/table/tr[3]/td/text()')[0].extract()
但是得不到,不知道xpath应该怎么写?


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
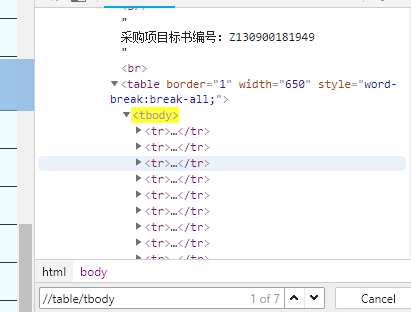 可以用浏览器的开发者工具,查看梳理过后的网页源代码,并输入xpath额外再检查一下 确认一下自己xpath是否写正确。(代码逐段打印出每个xpath对应的文本,进行比较 也可以用来查找错误)
可以用浏览器的开发者工具,查看梳理过后的网页源代码,并输入xpath额外再检查一下 确认一下自己xpath是否写正确。(代码逐段打印出每个xpath对应的文本,进行比较 也可以用来查找错误)
