

696
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
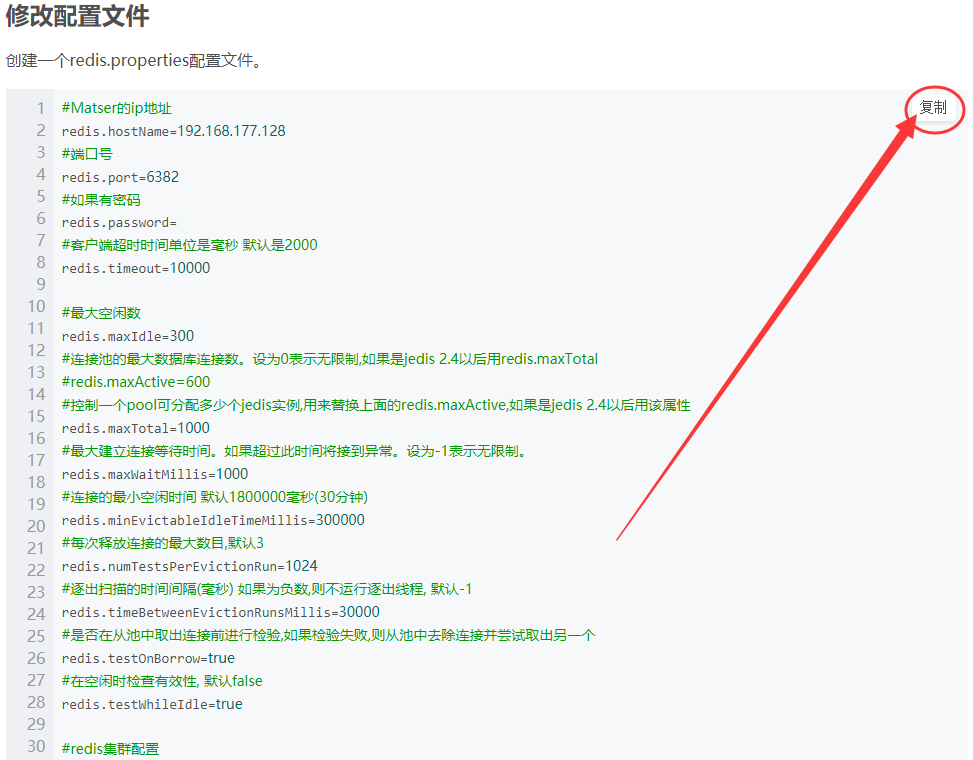 这里,复制代码
这里,复制代码






