22,296
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



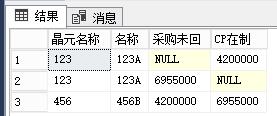
--测试数据
if not object_id(N'Tempdb..#T') is null
drop table #T
Go
Create table #T([晶元名称] int,[采购未回] INT,名称 NVARCHAR(23),CP在制 INT)
Insert #T
select 123,6955000,'123A',6955000 union all
select 456,4200000,'456B',6955000 union all
select 123,6955000,'123A',4200000
Go
--测试数据结束
SELECT t.晶元名称,名称,CASE WHEN rn1 =1 THEN t.采购未回 ELSE NULL END AS 采购未回,
CASE WHEN rn2 =1 THEN t.CP在制 ELSE NULL END AS CP在制 FROM (
SELECT *,ROW_NUMBER()OVER(PARTITION BY 晶元名称 ORDER BY 采购未回) rn1
,ROW_NUMBER()OVER(PARTITION BY 名称 ORDER BY CP在制) rn2 from #T
)t