27,579
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
DBCC SHOWCONTIG ('表名'); --查看表索引的碎片信息
dbcc dbreindex('('表名') --重新索引
DBCC INDEXDEFRAG (数据库名, 表名, 索引) --索引碎片整理


USE tempdb
GO
IF OBJECT_ID('tableA') IS NOT NULL DROP TABLE tableA
IF OBJECT_ID('tableB') IS NOT NULL DROP TABLE tableB
IF OBJECT_ID('tableC') IS NOT NULL DROP TABLE tableC
GO
--1000万 每个tableA中数据,关联tableB数据在1~20行之间
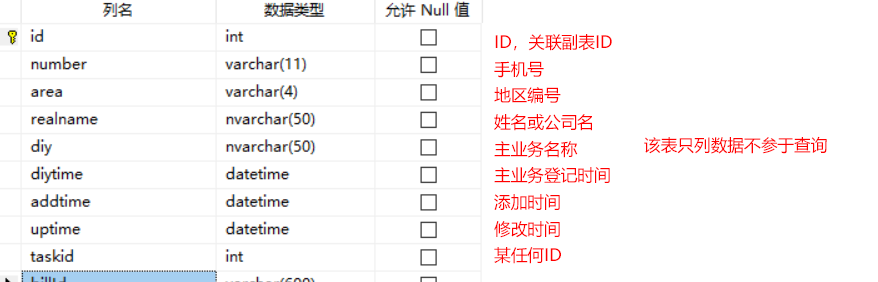
CREATE TABLE tableA(
id INT PRIMARY KEY,
number VARCHAR(11) NOT NULL,
realname NVARCHAR(50) NOT NULL,
diy NVARCHAR(50) NOT NULL,
diytime DATETIME NOT NULL,
addTime DATETIME NOT NULL,
uptime DATETIME NOT NULL,
taskid INT NOT NULL
)
--1亿 tableB中数据,diyname,存在大量重复情况,唯一性名称只有5000条
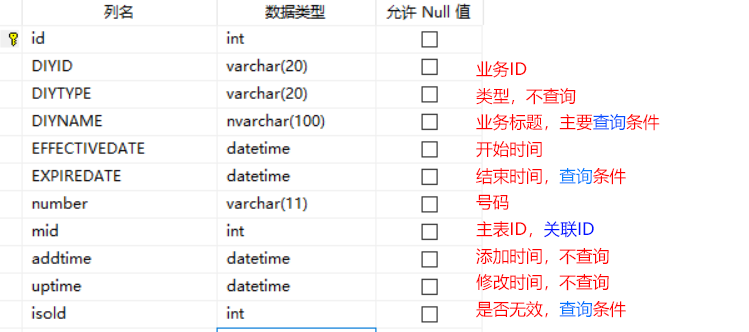
CREATE TABLE tableB(
id INT PRIMARY KEY,
diyid VARCHAR(20) NOT NULL,
diyType VARCHAR(20) NOT NULL,
diyname NVARCHAR(100) NOT NULL,
effectiveDate DATETIME NOT NULL,
[EXPIREDATE] DATETIME NOT NULL,
number VARCHAR(11) NOT NULL,
mid INT NOT NULL,
addTime DATETIME NOT NULL,
uptime DATETIME NOT NULL,
isold INT NOT NULL
)
CREATE INDEX ix_tableB_mid_diyid_EXPIREDATE ON tableB(mid,diyid,[EXPIREDATE])
--5000
CREATE TABLE tableC(
id INT PRIMARY KEY,
diyid VARCHAR(13) NOT NULL,
diyname NVARCHAR(60) NOT NULL,
diyType VARCHAR(30) NOT NULL,
islock INT NULL
)
GO
---- 以上为创建测试表 ----
---- 以下为修改后的查询
SELECT DIYID
INTO #tmp
FROM dbo.tableC
WHERE DIYNAME LIKE '%吃饭%'
CREATE CLUSTERED INDEX ix_#tmp ON #tmp(diyId)
SELECT COUNT(1)
FROM dbo.tableA AS a WITH(NOLOCK)
INNER JOIN dbo.tableB AS b WITH(NOLOCK)
ON a.id = b.mid AND a.taskid=1 AND b.isold=1
INNER JOIN #tmp AS tmp ON tmp.DIYID=b.diyid
--删除临时表
DROP TABLE #tmp;
--上面的脚本可能会比你原来快一点,但要秒出是不可能。
--优化, 本身只能是万里挑一。
--你这种 sql ,基本上没有过滤多少数据, 相当于扫全表,还要几个表连接。
--几乎没有更快的可能了,换 mysql, oracle 也一样。
--除非你加内存、换 SSD 硬盘并组 raid 。
--数据量这么大, 肯定只有一部分数据是需要的, 你要从业务上分析:只有哪些数据是必要的。
--建议从时间上来过滤, 比如:只取 1 个月内的数据……
--总之,最好是加上时间来过滤,并在时间字段上创建索引。
--注:除了主键的索引,前面不要加 id
--另外一个办法是做成报表, 凌晨处理好数据, 并存放到结果表, 查询时只查报表相关的结果表即可。
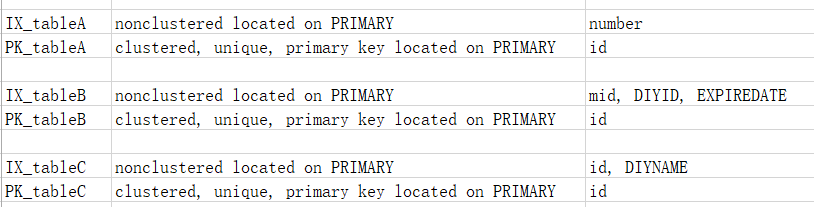
--查询 3 个表的索引情况,截图出来
EXEC sp_helpindex 'tableA' --实际表名请自己替换一下
EXEC sp_helpindex 'tableB'
EXEC sp_helpindex 'tableC'

SELECT count(1)
FROM dbo.tableA INNER JOIN
dbo.tableB ON dbo.tableA.id = dbo.tableB.mid
where taskid=1 and dbo.tableB.isold=1 and dbo.tableB.DIYID in(select DIYID from dbo.tableC where DIYNAME like '%吃饭%')