

22,296
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


--测试数据
if not object_id(N'Tempdb..#T') is null
drop table #T
Go
Create table #T([姓名] nvarchar(23),[结算日期] DATE,[项目名称] nvarchar(27))
Insert #T
select N'姓名1',N'2017-07-17',N'持续高流量吸氧' union all
select N'姓名2',N'2016-10-23',N'床位' union all
select N'姓名3',N'2017-07-26',N'持续高流' union all
select N'姓名4',N'2017-07-15',N'持续高流量吸氧' union all
select N'姓名5',N'2016-10-24',N'悬浮床' union all
select N'姓名6',N'2016-07-26',N'低流量吸氧' union all
select N'姓名7',N'2017-07-17',N'持续高流' union all
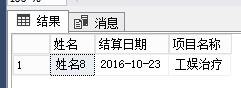
select N'姓名8',N'2016-10-23',N'工娱治疗' union all
select N'姓名9',N'2017-07-29',N'持续高流量吸氧' union all
select N'姓名9',N'2019-07-29',N'工娱治疗'
Go
--测试数据结束
Select * from #T WHERE
YEAR([结算日期])
BETWEEN 2016 AND 2017
AND [项目名称] IN (
'术后镇痛', '腰大池持续引流', '移动层流消毒床位费', '抗精神病药物治疗监测', '工娱治疗', '悬浮床治疗' --这些是想包含的项目
);

;WITH cte AS (
SELECT N'术后镇痛' AS item
UNION ALL SELECT N'腰大池持续引流'
UNION ALL SELECT N'移动层流消毒床位费'
UNION ALL SELECT N'抗精神病药物治疗监测'
UNION ALL SELECT N'工娱治疗'
UNION ALL SELECT N'悬浮床治疗'
)
SELECT * FROM t INNER JOIN cte
ON t.[项目名称] like '%'+cte.item+'%' and
(A.[结算日期] like '2016%' OR A.[结算日期] like '2017%')
;WITH cte AS (
SELECT N'术后镇痛' AS item
UNION ALL SELECT N'腰大池持续引流'
UNION ALL SELECT N'移动层流消毒床位费'
UNION ALL SELECT N'抗精神病药物治疗监测'
UNION ALL SELECT N'工娱治疗'
UNION ALL SELECT N'悬浮床治疗'
)
SELECT * FROM t INNER JOIN cte
ON t.[项目名称] like '%'+cte.item+'%' and A.[结平日期] like '%2017%'
SELECT
*
FROM
表
WHERE
YEAR([结平日期])
BETWEEN 2016 AND 2017
AND [项目名称] IN (
'术后镇痛', '腰大池持续引流', '移动层流消毒床位费', '抗精神病药物治疗监测', '工娱治疗', '悬浮床治疗'
);
YEAR([结算日期])
BETWEEN 2016 AND 2017
AND [项目名称] IN (
'术后镇痛', '腰大池持续引流', '移动层流消毒床位费', '抗精神病药物治疗监测', '工娱治疗', '悬浮床治疗' --这些名称不是模糊查询,如果想模糊查询,就用like 那种
);
