社区
Spark
帖子详情
Executor的Storage Memory一直缓慢增长,Spark自身不回收
Wayne_WY
2018-11-23 05:46:48
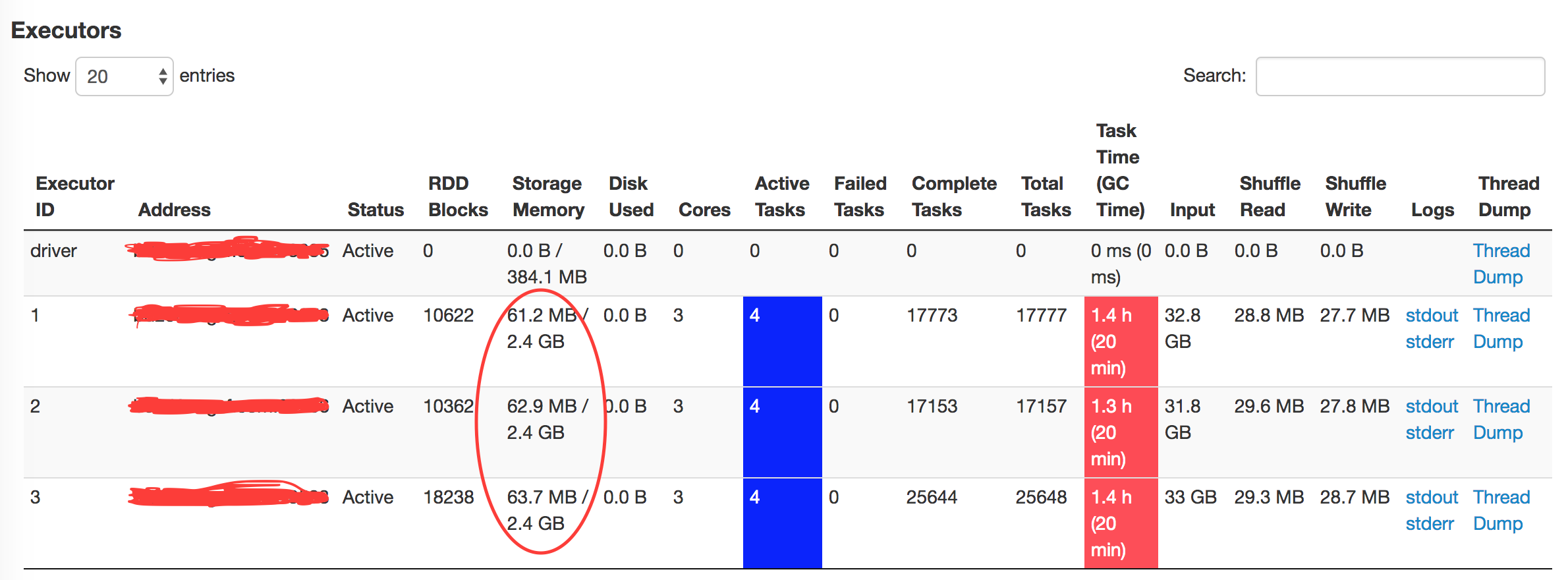
最近用Spark Streaming做实时计算,放到Yarn上跑了一段时间发现Storage Memory一直缓慢增长,每个batch大概涨个几M到几十M
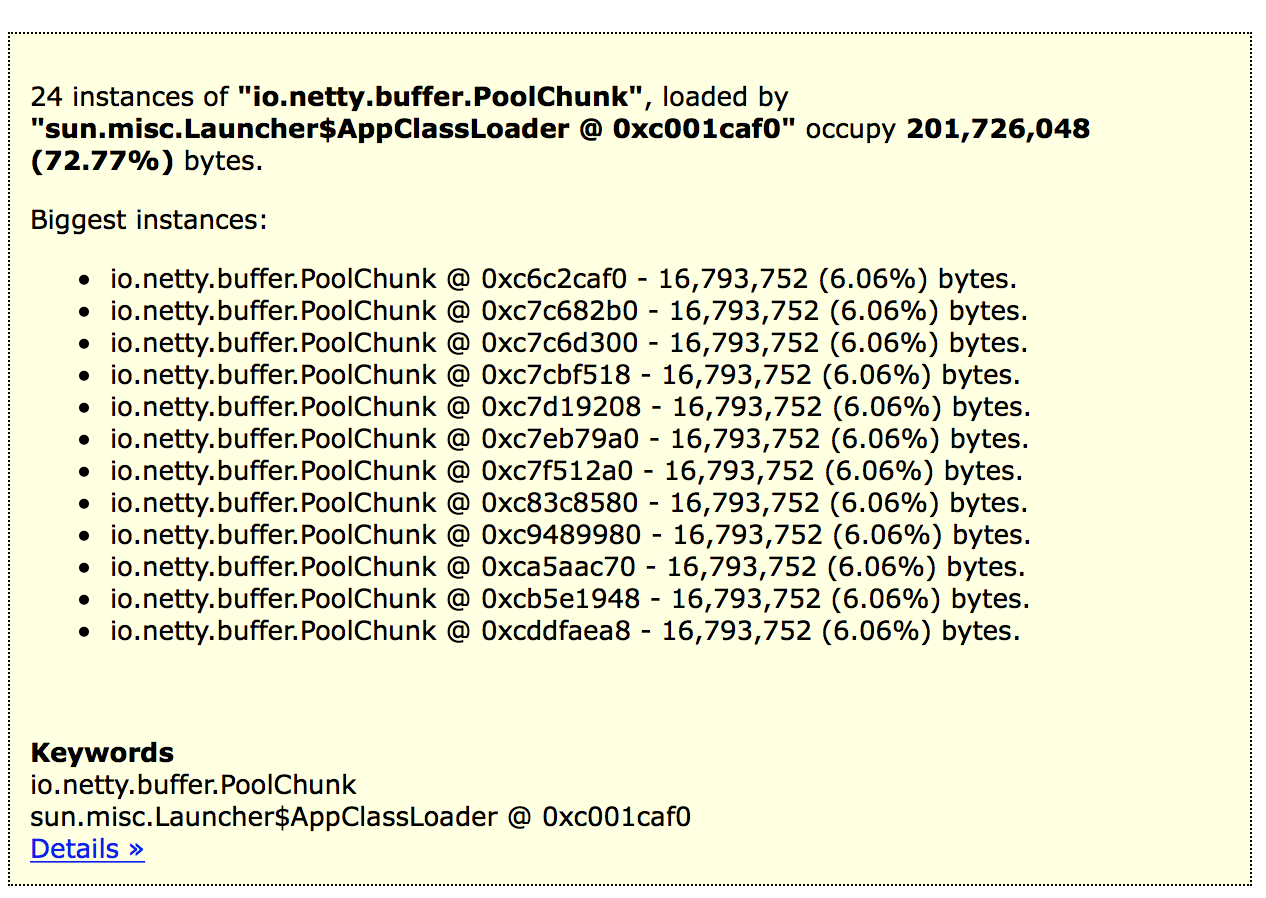
用内存泄漏查看得到如下结果
想问下问题大概出在哪里
...全文
440
4
打赏
收藏
Executor的Storage Memory一直缓慢增长,Spark自身不回收
最近用Spark Streaming做实时计算,放到Yarn上跑了一段时间发现Storage Memory一直缓慢增长,每个batch大概涨个几M到几十M 用内存泄漏查看得到如下结果 想问下问题大概出在哪里
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
4 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
无涯有涯
2018-11-27
打赏
举报
回复
我之前遇到过这样的问题,那时是因为存在未关闭的连接造成的
Wayne_WY
2018-11-27
打赏
举报
回复
程序里确实有写HBase,不过是单例模式的,连接池都有关闭了。看分析结果是netty创建了很多buffersize,这块不怎么了解
Wayne_WY
2018-11-27
打赏
举报
回复
引用 1 楼 yangjuanli 的回复:
不清楚,帮你友情UP一下。
多谢
yangjuanli
2018-11-26
打赏
举报
回复
不清楚,帮你友情UP一下。
大数据相关源代码阅读,包括
Spark
Core、
Spark
Sql、
Spark
Streaming、FlinkCore
大数据相关源代码阅读。包括
Spark
Core、
Spark
Sql、
Spark
Streaming、FlinkCore、ScalaLibrary、JavaSrc模块源码阅读。
Spark
Core包括部署Deploy模块、执行
Exec
u
tor
模块、内存
Memory
模块、调度Scheduler模块、经典的Shuffle模块、存储
S
tor
age
模块等。目前列出来的是比较核心常用的框架源码,包括: 基础编程语言:Java、Scala 数据处理框架:
Spark
、Flink 具体目录请见README.md
BigDataSourceCode:大数据相关源代码阅读(持续更新中...)。目前包括
Spark
Core,
Spark
Sql,
Spark
Streaming,FlinkCore,ScalaLibrary,JavaSrc模块源码阅读。
Spark
Core包括部署部署模块,执行执行器模块,内存存储模块,调度调度程序。模块,经典的Shuffle模块,存储模块等
前奏 本项目主要是大数据相关技术源码阅读。 随着大数据行情发展,支撑这个体系相关的技术也越来越多。 目前列出来的是比较核心常用的框架源码,包括: 基础编程语言:Java、Scala 数据处理框架:
Spark
、Flink 欢迎小伙伴一起加入阅读,夯实自己的技术,体验其中的乐趣。 持续更新中... 原始阅读 一,
spark
core源码阅读
Spark
Core模块源码阅读,版本2.2.0。 包括部署Deploy模块、执行
Exec
u
tor
模块、内存
Memory
模块、调度Scheduler模块、经典的Shuffle模块、存储
S
tor
age
模块等等。 1,部署模块源码 2,执行器模块源码 原始码:与各种可用管理器一起使用的
Exec
u
tor
组件。 3,内存模块源码 系统由两个主要组件组成,一个JVM范围的内存管理器和一个每个任务的内存管理器。 4,调度程序模块源码 原始:
Spark
的调度组件。这包括D
Spark
3.0.0 Driver 启动内幕
本课程讲解
Spark
3.0.0 Driver 启动内幕 的内容,包括:
Spark
Driver Program 剖析:
Spark
Driver Program、
Spark
Context 深度剖析、
Spark
Context 源码解析;DAGScheduler 解析:DAG 的实例化 、DAGScheduler 划分Stage 的原理、DAGScheduler 划分Stage 的具体算法、Stage 内部Task 获取位置的算法;TaskScheduler 解析:TaskScheduler 原理剖析、TaskScheduler 源码解析;SchedulerBackend 解析:SchedulerBackend 原理剖析、SchedulerBackend 源码解析、
Spark
程序的注册机制、
Spark
程序对计算资源
Exec
u
tor
的管理; 打通
Spark
系统运行内幕机制循环流程。
Spark
Exec
u
tor
内存管理
本文主要对
Exec
u
tor
的内存管理进行分析,下文中的
Spark
内存均特指
Exec
u
tor
的内存 堆内内存和堆外内存 作为一个 JVM 进程,
Exec
u
tor
的内存管理建立在 JVM 的内存管理之上,此外
spark
还引入了堆外内存(不在JVM中的内存),在
spark
中是指不属于该
exec
u
tor
的内存。 堆内内存:由 JVM 控制,由GC(垃圾
回收
)进行内存
回收
,堆内内存的大小,由
Spark
应用程序启动时的
exec
u
tor
-
memory
或
spark
.
exec
u
tor
.
memory
参
Spark
内存管理
spark
.
exec
u
tor
.
memory
/
spark
.
memory
.fraction/
spark
.
memory
.offHeap.size【堆外内存/内存管理】 钨丝计划
spark
.
exec
u
tor
.
memory
包含
spark
.
memory
.fraction;
spark
.
memory
.fraction 包含
spark
.
memory
.
s
tor
age
Fraction;
spark
2.4.5 Application Properties Property Name Default Meaning
spark
.app.name (none) The name of your application. This will appear in.
Spark
1,258
社区成员
1,168
社区内容
发帖
与我相关
我的任务
Spark
Spark由Scala写成,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于MapReduce算法实现的分布式计算。
复制链接
扫一扫
分享
社区描述
Spark由Scala写成,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于MapReduce算法实现的分布式计算。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章





 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


