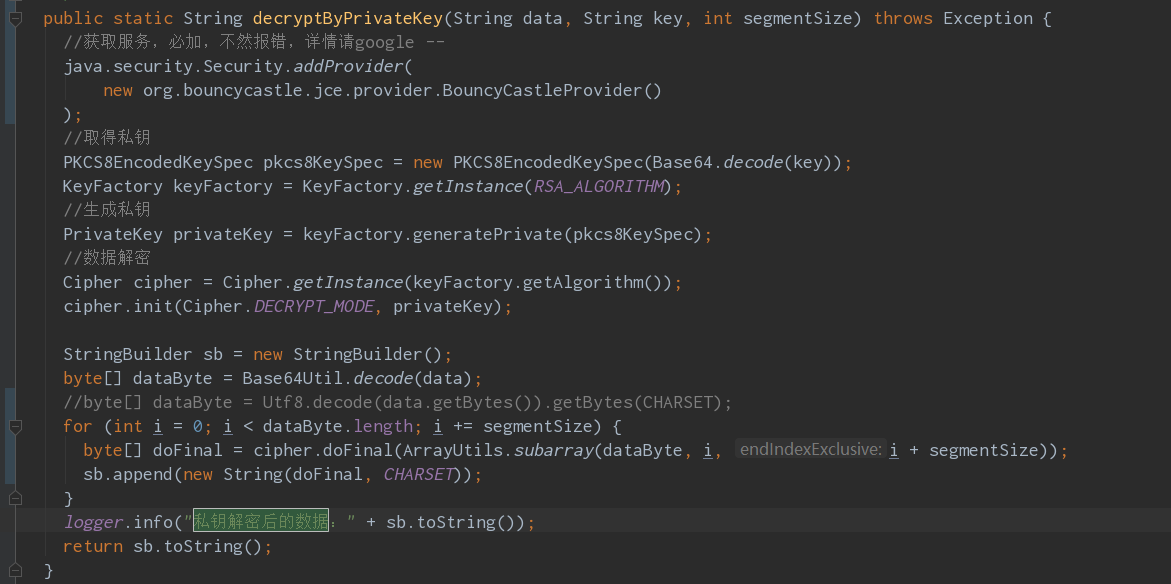
// 循环外定义 byte[] enBytes = null; // 循环里拼接 enBytes = ArrayUtils.addAll(enBytes, doFinal);
51,412
社区成员
86,032
社区内容
加载中
试试用AI创作助手写篇文章吧




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
 数组拼接:
数组拼接:






