62,623
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

class Temp {
public Temp() {
}
/**
* 获取标题
*/
public static StringBuffer getTitle(StringBuffer linkStr) throws Exception {
StringBuffer str = null;
Document document = Jsoup.connect(linkStr.toString()).get();
str = Conver.nsb(document.title());
return str;
}
/**
* 获取网页信息
*/
public static ArrayList<ArrayList<StringBuffer>> getTextAndLink(StringBuffer linkStr) throws Exception {
ArrayList<ArrayList<StringBuffer>> textAndLink = new ArrayList<ArrayList<StringBuffer>>();
textAndLink.add(new ArrayList<StringBuffer>());
textAndLink.add(new ArrayList<StringBuffer>());
Document document = Jsoup.connect(linkStr.toString()).get();
Elements links = document.select("a[href]");
for (Element link : links) {
textAndLink.get(0).add(Conver.nsb(link.text()));
textAndLink.get(1).add(Conver.nsb(link.attr("href")));
}
return textAndLink;
}
/**
* 获取html
*/
public static StringBuffer getHtml(StringBuffer linkStr) throws Exception {
StringBuffer str = null;
Document document = Jsoup.connect(linkStr.toString()).get();
str = Conver.nsb(document.html());
return str;
}
} public static void main(String[] args) throws Exception {
System.out.print("输入网址: ");
StringBuffer link = Input.nextLine();
ArrayList<ArrayList<StringBuffer>> data = Temp.getTextAndLink(link);
System.out.println();
for (int i = 0;i < data.get(0).size();++i) {
System.out.println(data.get(0).get(i) + " ---> " + data.get(1).get(i));
}
}

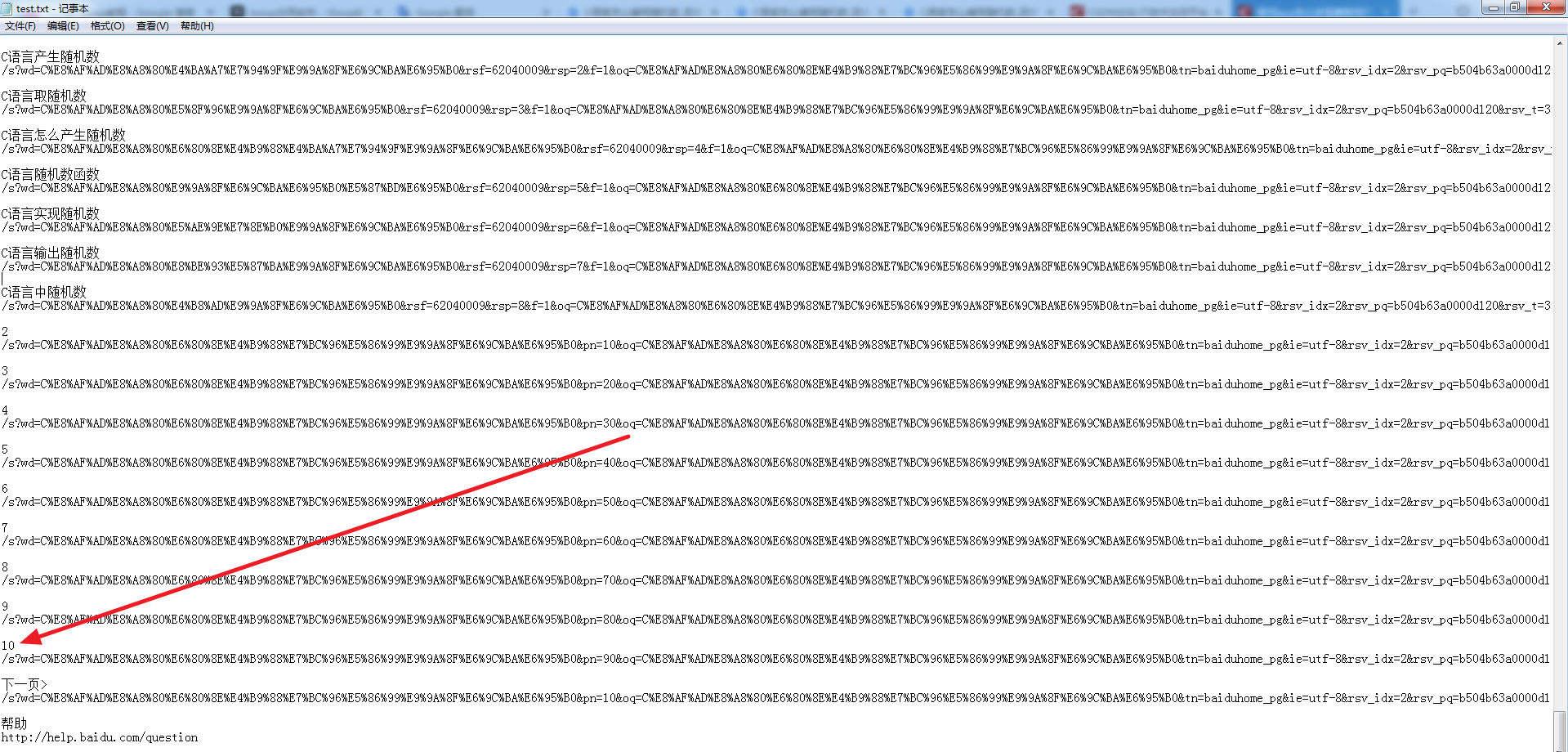
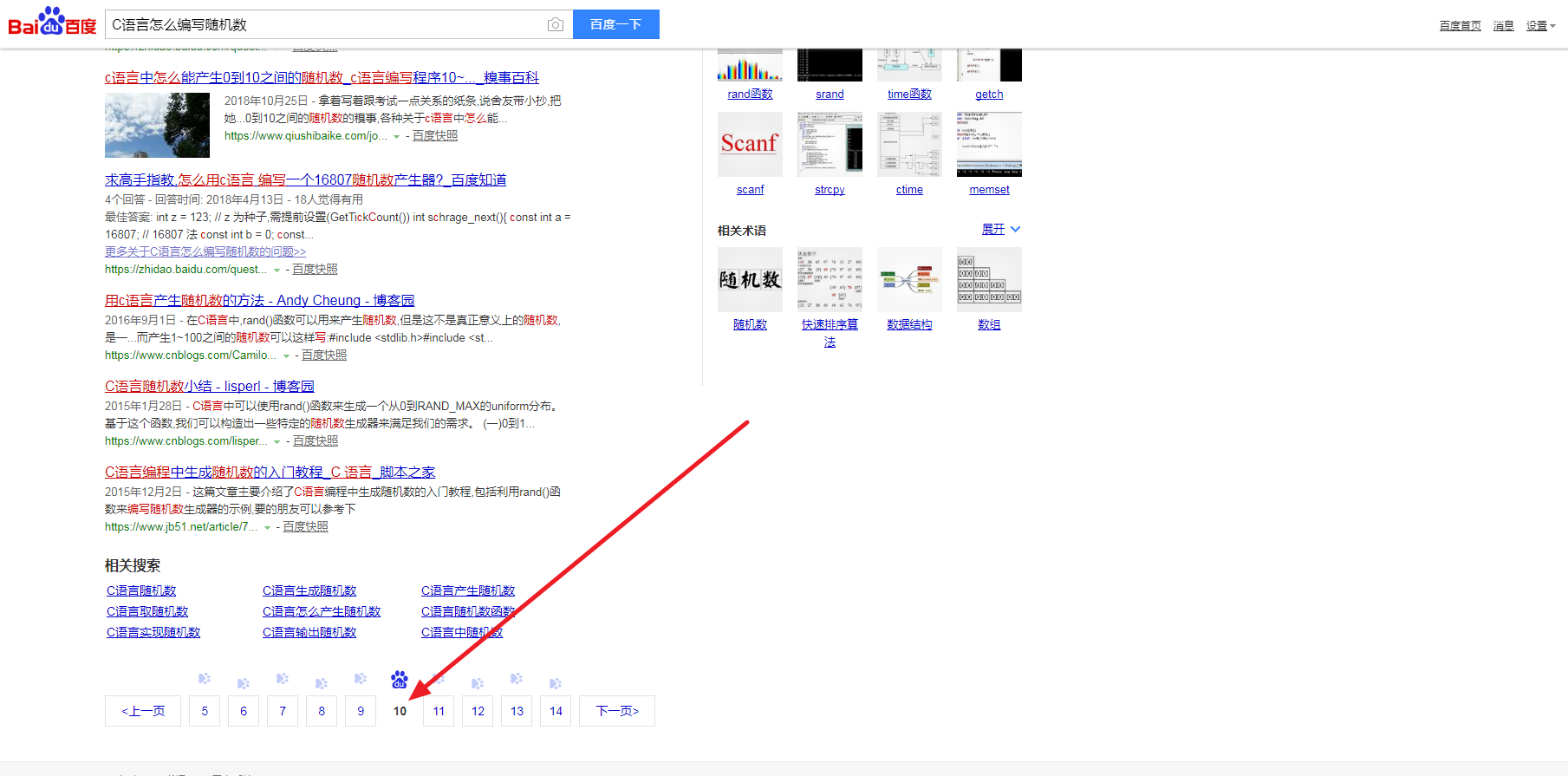
public static void main(String[] args) throws Exception {
String link = "https://www.baidu.com/s?wd=C%E8%AF%AD%E8%A8%80%E6%80%8E%E4%B9%88%E7%BC%96%E5%86%99%E9%9A%8F%E6%9C%BA%E6%95%B0&rsv_spt=1&rsv_iqid=0xbc83951500008d80&issp=1&f=8&rsv_bp=0&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_sug3=16&rsv_sug1=15&rsv_sug7=100&rsv_t=7649UHhrgN4vYkpzTa3Kx0XaSHMYWDMquHmKNVrk4CFQoDAcC0IUMtwZHMhVF%2FPZvsC7&rsv_sug2=0&inputT=8027&rsv_sug4=8850";
String path = "c:/下载/test.txt";
Document document = Jsoup.connect(link).get();
Elements links = document.select("a[href]");
String str = "";
for (Element cycle : links) {
str = cycle.text();
str += "\r\n";
str += cycle.attr("href");
WriteStr.write(path, str, "UTF8");
WriteStr.write(path, "\r\n", "UTF8");
WriteStr.write(path, "\r\n", "UTF8");
}
}