can't encode characters in position 0-2: ordinal not in range(128)
使用python3.7,WIN 7 企业版32位,SQL2008,代码如下:
# -*- coding: utf-8 -*-
"""
Created on Tue Dec 4 15:37:06 2018
@author: Administrator
"""
import pymssql
conn=pymssql.connect(host='22.139.123.11',user='yyuser',password='pwd',database='营业部',charset="utf8")
currsor=conn.cursor()
print(conn)
currsor.close()
conn.close()
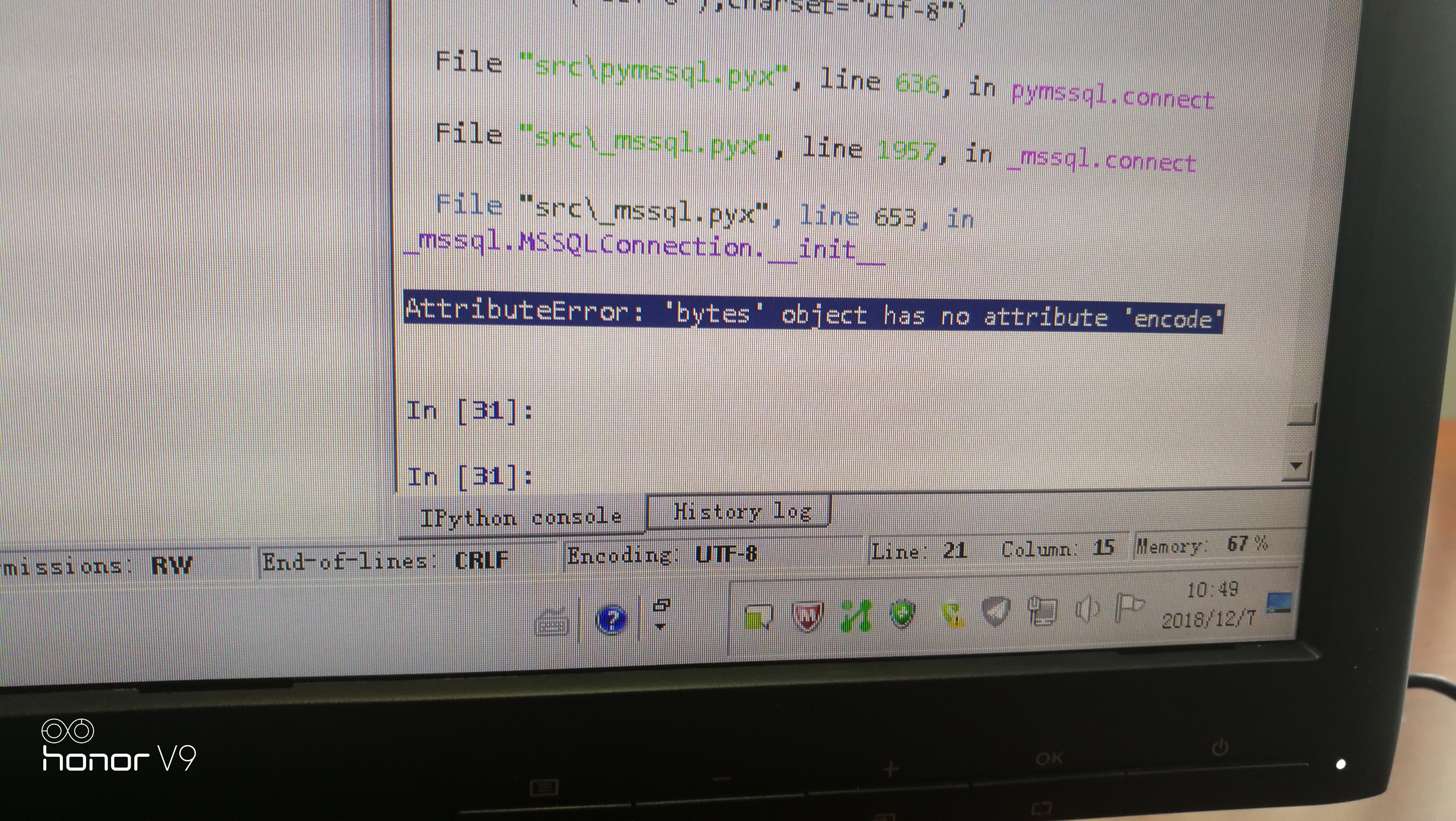
报错如下:
File "src\_mssql.pyx", line 653, in _mssql.MSSQLConnection.__init__
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-2: ordinal not in range(128)
上述代码文件使用 ue 打开后,显示 u8-DOS
网上查询了几个小时都未找到原因,希望在此得到高人指点。听说要转码,是因为我的数据库名称是“营业部“,但如何转呢?数据库里可是有不少中文名称的 database,与及中文名称的数据表呀


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享