kettle在保存作业时时候提示保存,同时资源库出现异常,打开其他操作都不行。断掉重连以后其他都正常。创建、编辑、保存其他的作业等等都没有问题,只有保存作业的时候报错。上周之前系统一切都正常的。资源库是PostgreSQL的。
保存作业时报错,图①:
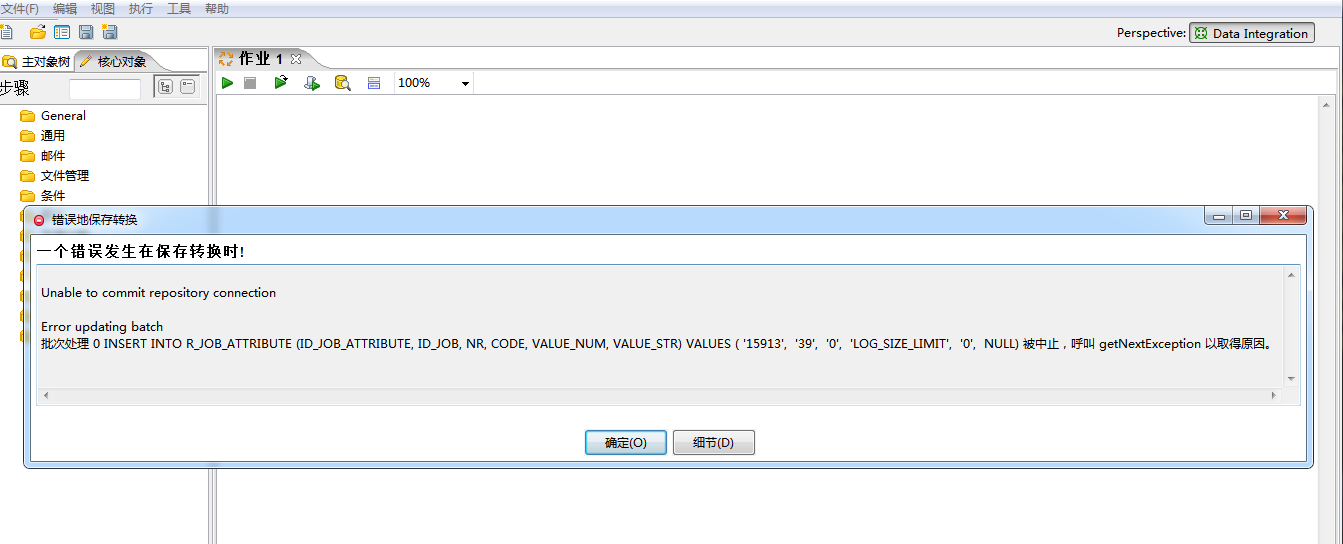
主要报错显示是一个SQL语句异常,在资源库中手动执行这个sql语句也显示异常,SQL语句如下:
INSERT INTO R_JOB_ATTRIBUTE (ID_JOB_ATTRIBUTE, ID_JOB, NR, CODE, VALUE_NUM, VALUE_STR) VALUES ( '15913', '39', '0', 'LOG_SIZE_LIMIT', '0', NULL)
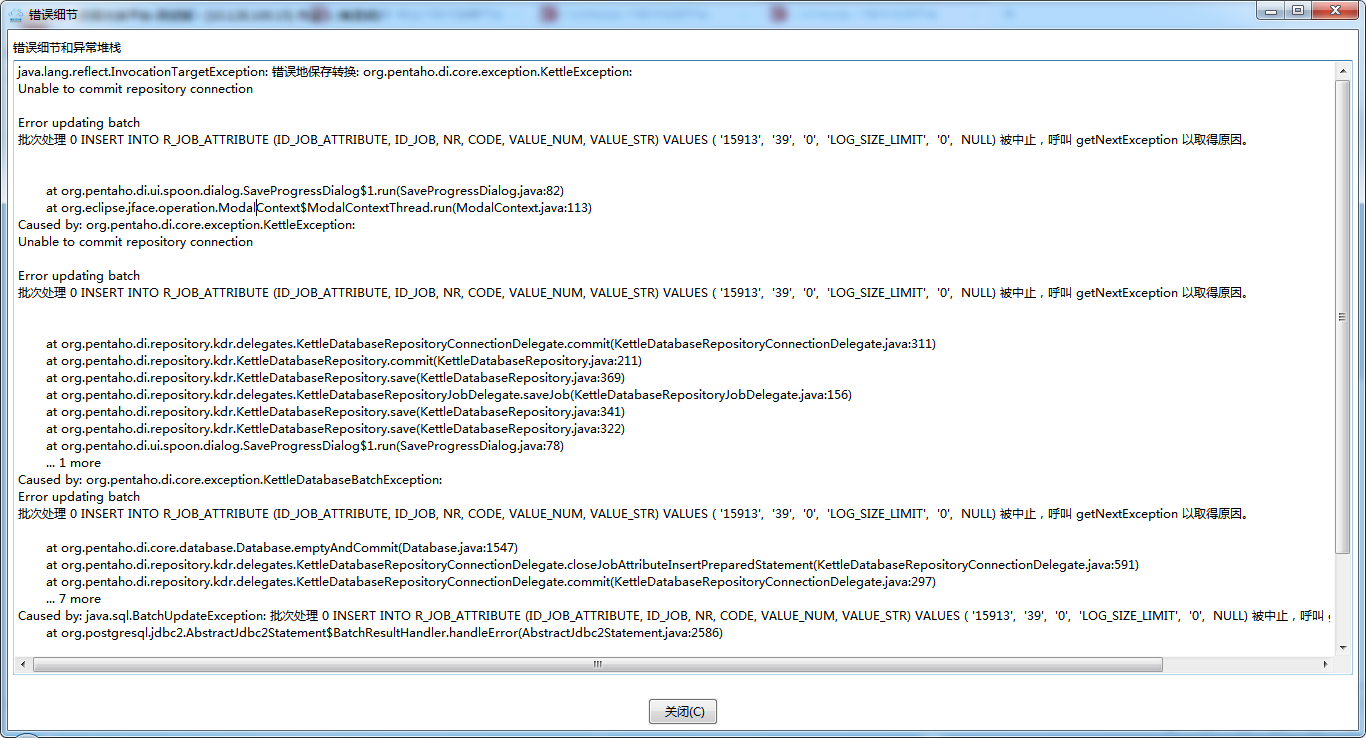
图①错误细节:
报错之后打开其他转换也异常了,图②:
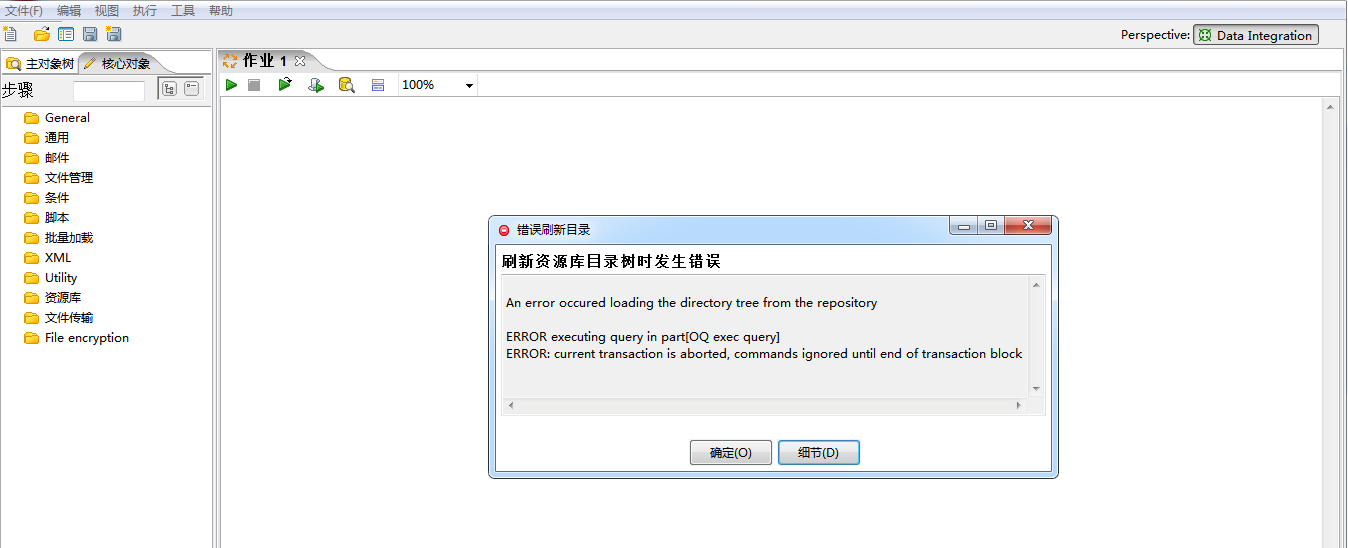
图②错误细节:
org.pentaho.di.core.exception.KettleException:
An error occured loading the directory tree from the repository
ERROR executing query in part[OQ exec query]
ERROR: current transaction is aborted, commands ignored until end of transaction block
at org.pentaho.di.repository.kdr.delegates.KettleDatabaseRepositoryDirectoryDelegate.loadRepositoryDirectoryTree(KettleDatabaseRepositoryDirectoryDelegate.java:107)
at org.pentaho.di.repository.kdr.KettleDatabaseRepository.loadRepositoryDirectoryTree(KettleDatabaseRepository.java:458)
at org.pentaho.di.ui.repository.dialog.SelectObjectDialog.open(SelectObjectDialog.java:339)
at org.pentaho.di.ui.spoon.Spoon.openFile(Spoon.java:3737)
at org.pentaho.di.ui.spoon.Spoon.openFile(Spoon.java:3688)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.pentaho.ui.xul.impl.AbstractXulDomContainer.invoke(AbstractXulDomContainer.java:329)
at org.pentaho.ui.xul.impl.AbstractXulComponent.invoke(AbstractXulComponent.java:139)
at org.pentaho.ui.xul.impl.AbstractXulComponent.invoke(AbstractXulComponent.java:123)
at org.pentaho.ui.xul.jface.tags.JfaceMenuitem.access$100(JfaceMenuitem.java:26)
at org.pentaho.ui.xul.jface.tags.JfaceMenuitem$1.run(JfaceMenuitem.java:85)
at org.eclipse.jface.action.Action.runWithEvent(Action.java:498)
at org.eclipse.jface.action.ActionContributionItem.handleWidgetSelection(ActionContributionItem.java:545)
at org.eclipse.jface.action.ActionContributionItem.access$2(ActionContributionItem.java:490)
at org.eclipse.jface.action.ActionContributionItem$5.handleEvent(ActionContributionItem.java:402)
at org.eclipse.swt.widgets.EventTable.sendEvent(Unknown Source)
at org.eclipse.swt.widgets.Widget.sendEvent(Unknown Source)
at org.eclipse.swt.widgets.Display.runDeferredEvents(Unknown Source)
at org.eclipse.swt.widgets.Display.readAndDispatch(Unknown Source)
at org.pentaho.di.ui.spoon.Spoon.readAndDispatch(Spoon.java:1226)
at org.pentaho.di.ui.spoon.Spoon.waitForDispose(Spoon.java:7056)
at org.pentaho.di.ui.spoon.Spoon.start(Spoon.java:8316)
at org.pentaho.di.ui.spoon.Spoon.main(Spoon.java:578)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.pentaho.commons.launcher.Launcher.main(Launcher.java:134)
Caused by: org.pentaho.di.core.exception.KettleDatabaseException:
ERROR executing query in part[OQ exec query]
ERROR: current transaction is aborted, commands ignored until end of transaction block
at org.pentaho.di.core.database.Database.openQuery(Database.java:1966)
at org.pentaho.di.repository.kdr.delegates.KettleDatabaseRepositoryConnectionDelegate.getIDs(KettleDatabaseRepositoryConnectionDelegate.java:1493)
at org.pentaho.di.repository.kdr.delegates.KettleDatabaseRepositoryDirectoryDelegate.getSubDirectoryIDs(KettleDatabaseRepositoryDirectoryDelegate.java:289)
at org.pentaho.di.repository.kdr.KettleDatabaseRepository.getSubDirectoryIDs(KettleDatabaseRepository.java:528)
at org.pentaho.di.repository.kdr.delegates.KettleDatabaseRepositoryDirectoryDelegate.loadRepositoryDirectoryTree(KettleDatabaseRepositoryDirectoryDelegate.java:97)
... 30 more
Caused by: org.postgresql.util.PSQLException: ERROR: current transaction is aborted, commands ignored until end of transaction block
at org.postgresql.core.v3.QueryExecutorImpl.receiveErrorResponse(QueryExecutorImpl.java:2077)
at org.postgresql.core.v3.QueryExecutorImpl.processResults(QueryExecutorImpl.java:1810)
at org.postgresql.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:257)
at org.postgresql.jdbc2.AbstractJdbc2Statement.execute(AbstractJdbc2Statement.java:498)
at org.postgresql.jdbc2.AbstractJdbc2Statement.executeWithFlags(AbstractJdbc2Statement.java:386)
at org.postgresql.jdbc2.AbstractJdbc2Statement.executeQuery(AbstractJdbc2Statement.java:271)
at org.pentaho.di.core.database.Database.openQuery(Database.java:1954)
... 34 more



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


