37,739
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享#encoding:utf-8
from django.shortcuts import render
from django.core.mail import send_mail
from django.conf import settings
from django.http import HttpResponse
def send_a(request):
# 发邮件
subject = '天天生鲜欢迎信息'
message = ''
sender = settings.EMAIL_FROM #"我的邮箱<1234567@qq,com>"
receiver = ["1234567@qq.com",]
send_mail(subject, message, sender, receiver, fail_silently=False)
return HttpResponse("ok")# 发送邮件配置
EMAIL_BACKEND = 'django.core.mail.backends.smtp.EmailBackend'
# smpt服务地址
EMAIL_HOST = 'smtp.qq.com'
EMAIL_PORT = 25
# 发送邮件的邮箱
EMAIL_HOST_USER = '983****201@qq.com'#授权码和邮箱没有公布出来
# 在邮箱中设置的客户端授权密码
EMAIL_HOST_PASSWORD = '***********'#授权码和邮箱没有公布出来
# 收件人看到的发件人
EMAIL_FROM = '天天生鲜<983****201@qq.com>'Internal Server Error: /
Traceback (most recent call last):
File "C:\Program Files\Python35\lib\site-packages\django\core\handlers\exception.py", line 34, in inner
response = get_response(request)
File "C:\Program Files\Python35\lib\site-packages\django\core\handlers\base.py", line 126, in _get_response
response = self.process_exception_by_middleware(e, request)
File "C:\Program Files\Python35\lib\site-packages\django\core\handlers\base.py", line 124, in _get_response
response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "F:\django_project\send_mail_test\myapp\views.py", line 15, in send_a
send_mail(subject, message, sender, receiver, fail_silently=False)
File "C:\Program Files\Python35\lib\site-packages\django\core\mail\__init__.py", line 60, in send_mail
return mail.send()
File "C:\Program Files\Python35\lib\site-packages\django\core\mail\message.py", line 291, in send
return self.get_connection(fail_silently).send_messages([self])
File "C:\Program Files\Python35\lib\site-packages\django\core\mail\backends\smtp.py", line 103, in send_messages
new_conn_created = self.open()
File "C:\Program Files\Python35\lib\site-packages\django\core\mail\backends\smtp.py", line 70, in open
self.connection.login(self.username, self.password)
File "C:\Program Files\Python35\lib\smtplib.py", line 693, in login
self.ehlo_or_helo_if_needed()
File "C:\Program Files\Python35\lib\smtplib.py", line 599, in ehlo_or_helo_if_needed
if not (200 <= self.ehlo()[0] <= 299):
File "C:\Program Files\Python35\lib\smtplib.py", line 439, in ehlo
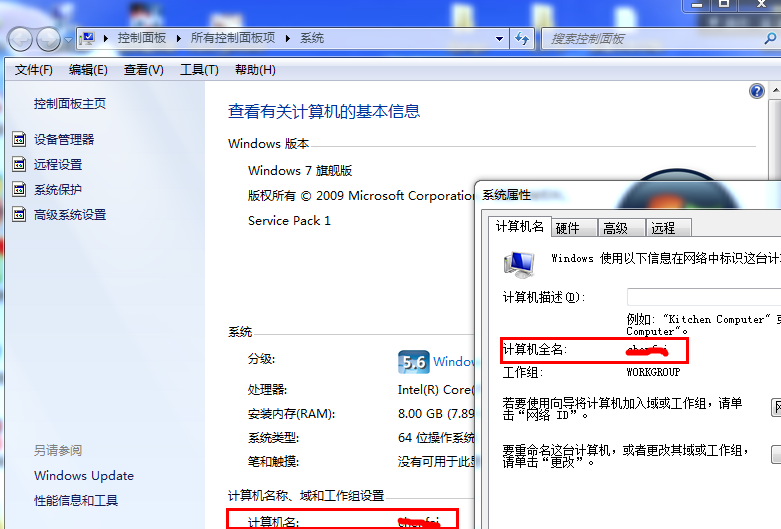
self.putcmd(self.ehlo_msg, name or self.local_hostname)
File "C:\Program Files\Python35\lib\smtplib.py", line 366, in putcmd
self.send(str)
File "C:\Program Files\Python35\lib\smtplib.py", line 351, in send
s = s.encode(self.command_encoding)
UnicodeEncodeError: 'ascii' codec can't encode characters in position 5-6: ordinal not in range(128)