3,881
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

 下面这个帖子有比较详细的描述。
https://cloud.tencent.com/info/3555e5e9ac8eadf44cef14719c317ff7.html
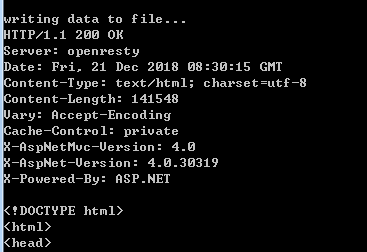
大概这样的:Transfer-Encoding: chunked字段可以看出响应体是否为 chunked 压缩,chunked 数据很有意思,采用的格式是 长度\r\n内容\r\n长度\r\n..0\r\n,而且长度还是十六进制的,最后以 0\r\n 结尾(不保证都有)。
下面这个帖子有比较详细的描述。
https://cloud.tencent.com/info/3555e5e9ac8eadf44cef14719c317ff7.html
大概这样的:Transfer-Encoding: chunked字段可以看出响应体是否为 chunked 压缩,chunked 数据很有意思,采用的格式是 长度\r\n内容\r\n长度\r\n..0\r\n,而且长度还是十六进制的,最后以 0\r\n 结尾(不保证都有)。


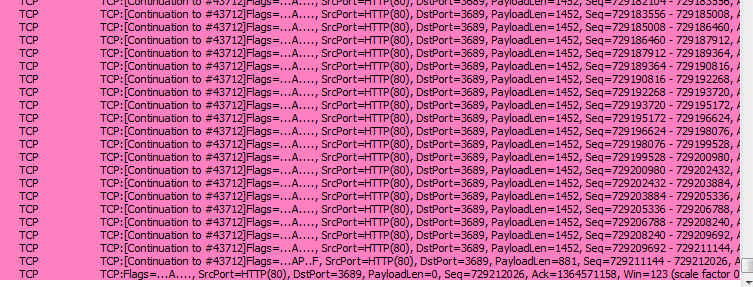
Content-Length: 72838