

27,579
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享select c_swunit_data_id,sum(c_value) as number,c_swstation_id,c_value,c_get_time from t_swunit_data_his
group by c_swunit_data_id
--测试数据
if not object_id(N'Tempdb..#T') is null
drop table #T
Go
Create table #T([c_swunit_data_id] int,[c_get_time] Date,[c_value] int)
Insert #T
select 1,'2018-12-10',10 union all
select 1,'2018-12-12',10 union all
select 2,'2018-12-13',10 union all
select 3,'2018-12-15',10
Go
--测试数据结束
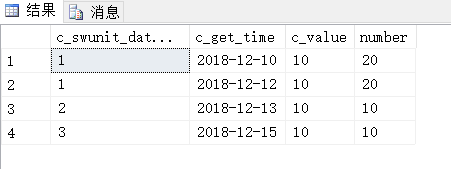
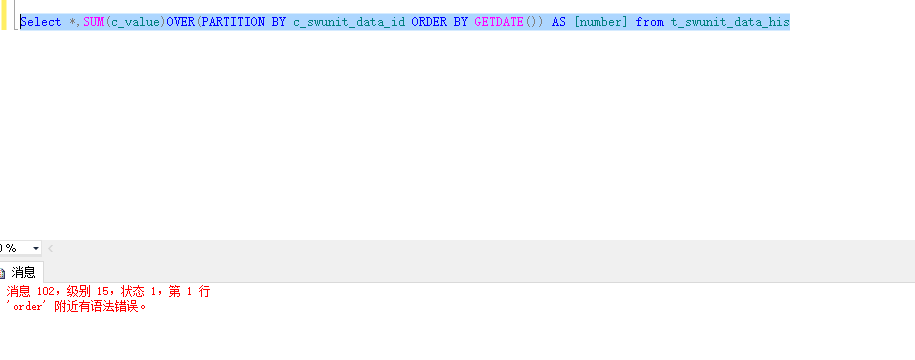
Select *,SUM(c_value)OVER(PARTITION BY c_swunit_data_id ORDER BY GETDATE()) AS [number] from #T

SELECT c_swunit_data_id,
SUM(c_value) AS number,
c_swstation_id,
c_value,
c_get_time
FROM t_swunit_data_his
GROUP BY
c_swunit_data_id,
c_swstation_id,
c_value,
c_get_time

--测试数据
if not object_id(N'Tempdb..#T') is null
drop table #T
Go
Create table #T([c_swunit_data_id] int,[c_get_time] Date,[c_value] int)
Insert #T
select 1,'2018-12-10',10 union all
select 1,'2018-12-12',10 union all
select 2,'2018-12-13',10 union all
select 3,'2018-12-15',10
Go
--测试数据结束
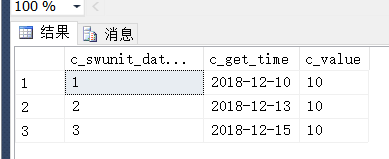
SELECT t.c_swunit_data_id,t1.c_get_time,t1.c_value FROM (
SELECT c_swunit_data_id,SUM(c_value)c_value FROM #T GROUP BY c_swunit_data_id)t
CROSS APPLY(SELECT TOP 1 * FROM #T WHERE t.c_swunit_data_id = c_swunit_data_id)t1
 [/quote]
[/quote]
if not object_id(N'Tempdb..#T') is null
drop table #T
Go
Create table #T([c_swunit_data_id] int,[c_get_time] Date,[c_value] int)
Insert #T
select 1,'2018-12-10',10 union all
select 1,'2018-12-12',10 union all
select 2,'2018-12-13',10 union all
select 3,'2018-12-15',10
Go
--测试数据结束
;
with list as(
select [c_swunit_data_id],sum([c_value]) as sum_c_value
from #T
group by [c_swunit_data_id]
)
select a.*,b.sum_c_value
from #T a
inner join list b on a.[c_swunit_data_id]=b.[c_swunit_data_id]SELECT c_swunit_data_id,
SUM(c_value) AS c_value
FROM 表
GROUP BY c_swunit_data_id;
