社区
Informatica
帖子详情
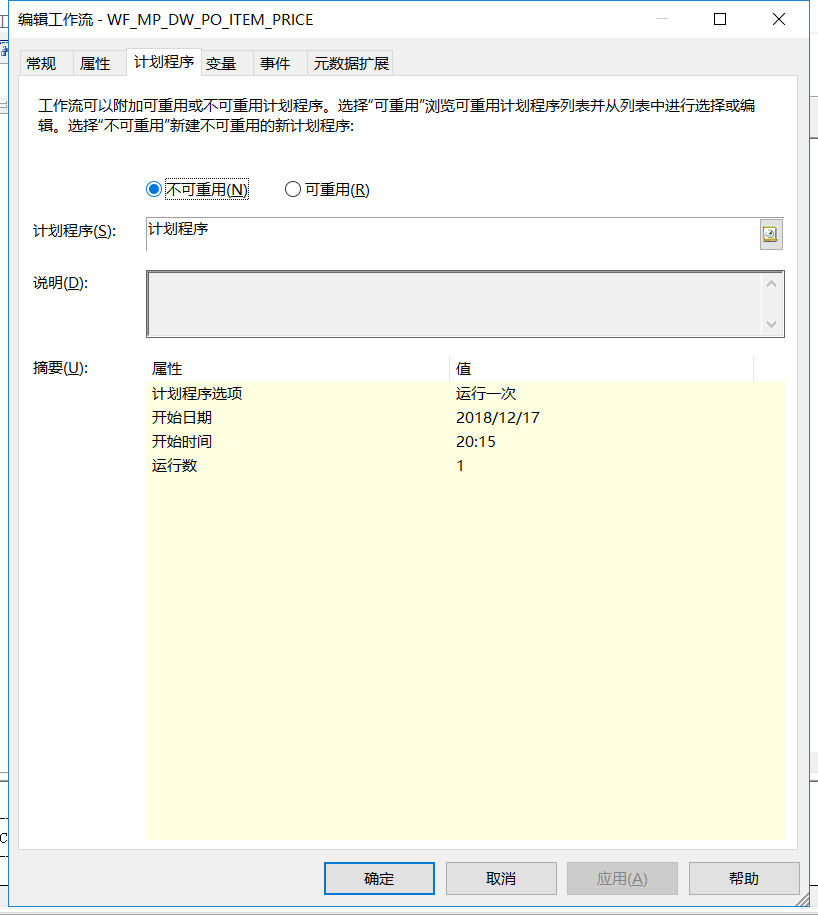
workflow怎么添加计划没用
Boil_ou
2018-12-17 08:21:21
workflow怎么添加计划
...全文
66
回复
打赏
收藏
workflow怎么添加计划没用
workflow怎么添加计划
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
workflow
添加
html,为alfred编写
workflow
最近用上了alfred,感觉特别好用。尤其是
workflow
的功能,简直不能更赞。在网上找了下,没发现特别号的编写
workflow
的教程。虽然很简单,还是分享给大家,希望能帮助到更多的朋友,也希望有更多更好的
workflow
出现。 下面是一个简单的例子。第一个worklfow用sublime打开当前文件夹熟话说要学一个东西得先会模仿。现在我们要做一个用sublime打开当前finder所在文件夹的...
GitLab
WorkFlow
在团队开发中,为了更好的协作,通常会采用一些工作流来最大程度提升效率。生产一个软件工序是比较复杂的,如果通过一个好的逻辑顺序去应用到一个软件开发的生命周期过程是非常重要的。 GitLab
WorkFlow
从构思到上线的十步 想法:每一个新建议都从一个想法开始,可以尝试下头脑风暴等聊天的形式。 问题:讨论想法的最有效方法是为其提出问题,例如是否可实现。
计划
:讨论如果达成一致的意见,就需要确定实施细节及优先级。 代码:一旦有了任务就可以开始编写代码了。 提交:针对需求编写的代码完成后就可以提交到功能分.
Oracle
WorkFlow
基础笔记
1.
Workflow
Builder的默认访问级别是100,以下是Oracle对访问级别的一个大致分类:0-9 Oracle
Workflow
10-19 Oracle Application Object Library20-99 Oracle Application Development100-999 Customer Organization1000 Public2. Oracle 工作
Alfred for window
添加
workflow
不起作用
添加
workflow
后的关键字不起作用 原因:
workflow
添加
后需要重启Alfred
Alfred之
workflow
入门
前言小帽子alfred可以说是macOS上最佳的效率软件了,而其中最强大的功能就属alfred 2.0推出的
Workflow
特性了。就像我们工程师遇到重复性工作总是想写脚本或者程序来解放自己一样,
workflow
功能允许你将日常重复性的工作通过使用脚本语言(bash、zsh、php、ruby、python、perl、as、js)封装起来,通过alfred作为统一入口进行使用。因为alfred的受众...
Informatica
248
社区成员
377
社区内容
发帖
与我相关
我的任务
Informatica
讨论 Informatica 数据集成相关技术、数据隐私保护相关技术
复制链接
扫一扫
分享
社区描述
讨论 Informatica 数据集成相关技术、数据隐私保护相关技术
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章

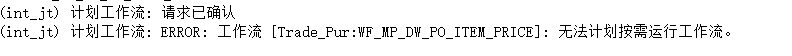


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享