社区
脚本语言
帖子详情
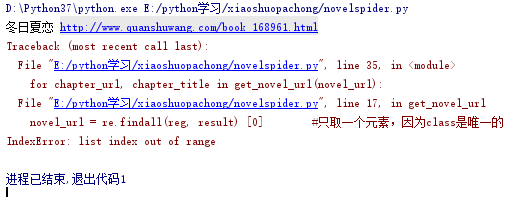
请问下我跟一个视频写的爬一个小说网站的爬虫程序,视频理没问题,出现这个问题怎么解决
zwl2253226757
2019-01-04 10:22:36
...全文
484
2
打赏
收藏
请问下我跟一个视频写的爬一个小说网站的爬虫程序,视频理没问题,出现这个问题怎么解决
[图片]
复制链接
扫一扫
分享
转发到动态
举报
AI
作业
写回复
配置赞助广告
用AI写文章
2 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
jeky_zhang2013
2019-01-11
打赏
举报
回复
单独用网页字符试下正则能否正确匹配
Mr.Zheng~_
2019-01-05
打赏
举报
回复
没有获取到元素~所以索引超出范围就会报错~应该是你的正则匹配错了~_
十四天——我都经历了
爬
虫
的哪些坑(一些心得与反思,仅以次纪念,不作参考)
直接进入正题(记录我初学
爬
虫
的一些心得): 我
爬
的是豆瓣的电影,具体项目有电影名称、导演名、演员名、影片类型、影片海报、还有部分关于电影的短评(太多了的话
爬
一次时间太长,不太好往数据库里存)先上最后...
Python
爬
虫
概念及小说文章案例
本文参考博主咕噜咕噜啦啦文章Python
爬
虫
入门_
爬
虫
代码入门csdn-CSDN博客python
爬
虫
实战训练_python
爬
虫
练习-CSDN博客,其中小说乱码
问题
参考的博客园博主昵称RChow文章Python
爬
虫
--
爬
取文字加密的番茄小说 - RChow ...
5.20
爬
虫
结——Mu
3852724,最新版墨镜风格模板发布了,有需要的朋友可以进来看看,2759280 3856589,官方手机模板在哪安装,3140684 ...3856513,
请问
这个网站用的是什么应用
程序
,3140310 3856515,萌新想问一下,能否可以实现现在主流素
题解 | #nginx日志分析5-统计
爬
虫
抓取404的次数#
节前过了一面,你就自我介绍也不让我说,技术也不问,就问了
一个
线程池项目,不停的问和别的线程池比你的优秀在哪,然后象征性的问了几个奇怪到极点的八股,然后就开始你的。弹性工作制 不打卡上班!
【精选】基于大数据的图书推荐系统设计与实现(源码+定制+开发)个性化推荐算法、用户行为分析、分布式数据处理与存储 用户阅读偏好分析、大数据驱动的个性化推荐平台、图书推荐算法设计
✌我是阿龙,一名专注于Java技术领域的
程序
员,全网拥有10W+粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台的优质...
脚本语言
37,743
社区成员
34,212
社区内容
发帖
与我相关
我的任务
脚本语言
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
复制链接
扫一扫
分享
社区描述
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


