社区
Hadoop生态社区
帖子详情
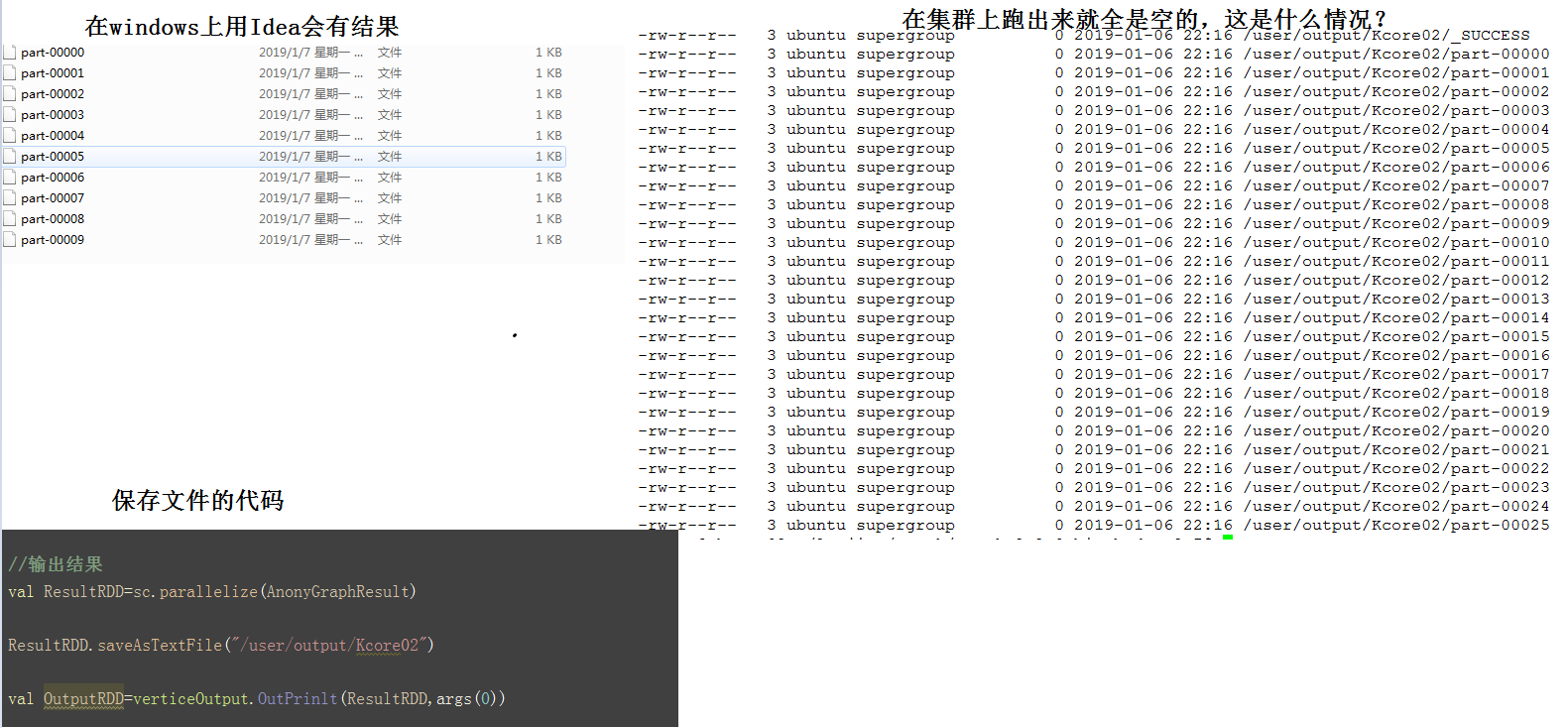
Spark运行结果为空
知己比邻
2019-01-07 10:41:40
在本机电脑电脑上跑有结果,上集群全是空结果,为啥?快要疯了
...全文
626
3
打赏
收藏
Spark运行结果为空
在本机电脑电脑上跑有结果,上集群全是空结果,为啥?快要疯了
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
3 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
AI_Maynor
2021-05-07
打赏
举报
回复
是不是楼上说的?
chongchongone
2021-04-26
打赏
举报
回复
有可能是目录权限问题 首先要确认在HDFS上:/user/output/Kcore02 目录是否存在
前方的灯
2021-02-01
打赏
举报
回复
我也是啊,楼主解决了吗?
spark
写入hadoop
为空
这个主要是因为我使用的本地开发,然后是使用的阿里的服务器,导致写入到hdfs的时候文件写入进去了,但是一直写的都是空文件,
Spark
2.4
运行
空指针异常10582
Spark
2.4
运行
空指针异常105821.确认问题2. 快速解决 1.确认问题
spark
版本: 2.4.0 报错问题 : Exception in thread “main” java.lang.ArrayIndexOutOfBoundsException: 10582 2. 快速解决 添加一个pom依赖 <dependency> <groupId>com.thoughtworks.paranamer</groupId> <artif
spark
创建空dataframe
源码中已经很明确告诉我们,emptyDataFrame创建了一个不含任何行列且schema
为空
的dataframe。项目中会需要用到创建空的dataframe。
spark
提供了emptyDataFrame方法,可以直接创建。错误信息也很直观,emptydf是0 columns,df是2 columns,所以无法直接union。为了解决上面的问题,我们需要在生成emptyDataFrame的时候指定schema。这个空的dataframe在实际中用途有限,比如如下场景。上面的方法
运行
时候直接抛出错误信息。
Spark
的
运行
流程
目录 1.1、
Spark
的基本
运行
流程 1.2、
运行
流程图解 1.3、
Spark
Context初始化 1.4、
Spark
运行
架构特点 1.5、DAScheduler 1.6、TaskScheduler 1.7、SchedulerBackend 1.8、Executor 1.1、
Spark
的基本
运行
流程 1、构建 DAG 使用算子操作 RDD 进行各种 transfor...
spark
之如何创建空的RDD
spark
之如何创建空的RDD 1 创建没有分区的空 RDD 在
Spark
中,对
Spark
Context 对象使用 emptyRDD() 函数会创建一个没有分区或元素的空 RDD。 下面的示例创建一个空 RDD。 In
Spark
, using emptyRDD() function on the
Spark
Context object creates an empty RDD with no partitions or elements. The below examples create an
Hadoop生态社区
20,808
社区成员
4,690
社区内容
发帖
与我相关
我的任务
Hadoop生态社区
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
复制链接
扫一扫
分享
社区描述
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



