使用查询字符串为:strSQL = "select cpdm,cpmc,SUM(sl) from ckrk where sl>0 AND rq BETWEEN '" & DateA & "' AND '" & DateB & "' GROUP BY cpdm,cpmc"。
sl的汇总结果不是两个日期之间的满足条件所有数据总和,只显示了最后一个日期数据记录
...全文
35712打赏收藏
SQL求和语句里只汇总了最后一条记录,不知为什么 ?
使用查询字符串为:strSQL = "select cpdm,cpmc,SUM(sl) from ckrk where sl>0 AND rq BETWEEN '" & DateA & "' AND '" & DateB & "' GROUP BY cpdm,cpmc"。 sl的汇总结果不是两个日期之间的满足条件所有数据总和,只显示了最后一个日期数据记录


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

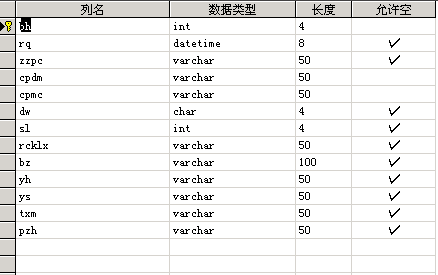 表结构及SQL代码
表结构及SQL代码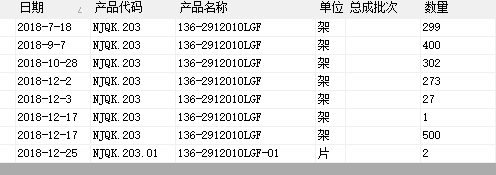 在BETWEEN '2018-5-26' AND '2018-12-25'范围内只汇总了NJQK.203分组的12月份的几笔数据,和为801,汇总不全。
在BETWEEN '2018-5-26' AND '2018-12-25'范围内只汇总了NJQK.203分组的12月份的几笔数据,和为801,汇总不全。






