

37,739
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享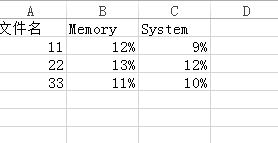



import os
import re
import xlrd,xlwt
def find_files(s_path):
res = {}
file_list = os.listdir(s_path)
for filename in file_list:
abs_filename = os.path.join(s_path,filename)
if os.path.isfile(abs_filename):
#打开文件
with open(abs_filename,"r",encoding="utf8") as f:
for line in f:
m1 = re.search("^Memory Using.*\s+(\d+%)$",line)
if m1:
m_data = m1.group(1)
m2 = re.search("^System CPU Using.*\s+(\d+%)$",line)
if m2:
cpu_data = m2.group(1)
res[abs_filename] = (m_data,cpu_data)
elif os.path.isdir(abs_filename):
find_files(abs_filename)
else:
print("不是文件夹,也不是文件")
return res
#创建excel 文件
def write_excel(data):
writebook = xlwt.Workbook() # 打开一个excel
sheet = writebook.add_sheet('data') # 在打开的excel中添加一个sheet
# 添加表头
sheet.write(0,0,'文件名')
sheet.write(0, 1, '内存占比')
sheet.write(0, 2, 'CPU占比')
# 65535 最大行,可以自行拆分
for index,item in enumerate(data):
sheet.write(index+1,0,item) # 文件名
sheet.write(index+1,1,data[item][0])
sheet.write(index+1,2,data[item][1])
writebook.save("result.xls")
if __name__ == "__main__":
s = r"E:\Computer\Python\Code\系统模块\test" #更换自己的路径
res = find_files(s)
write_excel(res)

def seek_files(check_path, ext_key):
# 列出文件夹下所有ext_key 后缀的文件,不处理子目录
list_files = []
cur_list = os.listdir(check_path)
for i in range(0 ,len(cur_list)):
file_path = os.path.join(check_path, cur_list[i])
if os.path.isfile(file_path):
if cur_list[i].upper().find(ext_key.upper()) > 0:
list_files.append([cur_list[i], file_path])
return list_files
txt_list = seek_files(r'D:\demo','txt')

