社区
C#
帖子详情
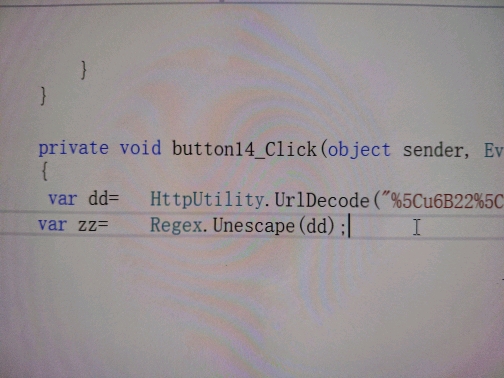
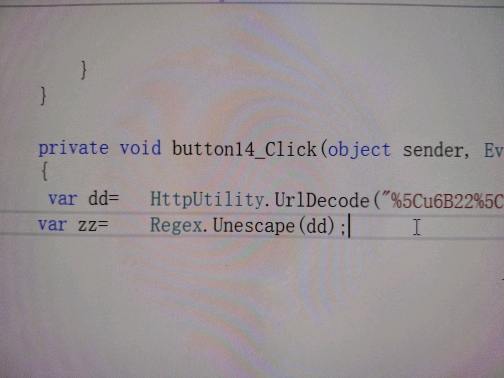
c#中编码 usc2转ansi
u010313100
2019-02-08 01:17:07
一个regex.unescape()直接搞定, 我可是纠结了几个小时
...全文
944
9
打赏
收藏
c#中编码 usc2转ansi
一个regex.unescape()直接搞定, 我可是纠结了几个小时
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
9 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
钢铁侠找不到回家的路了
2019-02-13
打赏
举报
回复
留个脚印 以后有可能用得上
手在键盘敲很轻
2019-02-13
打赏
举报
回复
留个痕迹,待后用
xiaoxiangqing
2019-02-13
打赏
举报
回复
OrdinaryCoder
2019-02-13
打赏
举报
回复
留个痕迹,万一以后用到了呢
娃都会打酱油了
2019-02-12
打赏
举报
回复
好吧,我也是头一次知道
xuzuning
2019-02-12
打赏
举报
回复
楼主原本纠结的是:如何将
\u6b22\u8fce
转换成
欢迎
突然发现用 Regex.Unescape 就可以了 故分享之! 不劳大师们点评,我也是头一次知道
良朋
2019-02-12
打赏
举报
回复
楼主也是一个Smart的CSDNer,上代码直接截图。
非专业开发Five
2019-02-11
打赏
举报
回复
你的纠结是对的,你这只是把uriencode转换为系统当前默认编码,并没有转换usc2到ansi。 但是uriencode是大于usc2的编码集,一般系统默认编码是ansi,所以你的结果没有错。
threenewbee
2019-02-08
打赏
举报
回复
你的问题是什么,你要注意本身你的url要合法,比如说汉字,是4个十六进制组成的而不是2个。
usc2
转
ansi
php,C++高手帮忙修改实现
usc2
转
ansi
[C++] 纯文本查看 复制代码std::string
usc2
To
Ansi
(std::string str){str = replaceAll(str, "\\u", "0X");std::string::size_type pos(0);while (std::string::npos != (pos = str.find("0X", pos))){std::string tmpString ...
usc2
转
ansi
php,将
Ansi
转
换为
usc2
的步骤是什么
[AppleScript] 纯文本查看 复制代码.版本 2.子程序
编码
_
Ansi
到ucs2_2, 文本型, 公开, UCS2 也就是 unicode be,ucs2是2字节的UNICODE
编码
,还有UCS4,也就是4字节的UNICODE
编码
。将
ansi
转
变成
usc2
,如 123
转
换后为 %u0031%u0032%u0033,失败返回空文本;如“王”字:Unicode为738BH,若按Un...
字符
编码
方式及判断整理(
ANSI
,Unicode,utf-8,utf-16,utf-32)
一、
编码
方式 说
编码
之前,先扯个淡!大家都知道计算机只能识别1和0,
编码
就是将不同的符号与1和0的组合进行一下映射,做到能够表示哪个组合能够对应那个字符,由于早期的不能预料到未来的情况,后续互联网扩张后又要做到兼容,就出现了五花八门的
编码
。还值得一说的是计算机的处理一般面向字节或者字,位的操作也应该是通过对字节处理来模拟的。
编码
的长度一般都以字节来算。 学习C语言的同学最刚开
utf8
转
ucs2
编码
c语言实现,C++字符
转
换
UTF_8与GBK在windows平台下sizeof(wchar_t)为2,而在linux平台下sizeof(wchar_t)为4;在windows平台下宽字符(或字符串)字面量使用UTF-16
编码
,linux平台下使用UTF-32
编码
。MultiByteToWideChar、WideCharToMultiBytestd::string UTF8ToGBK(const std::string&am...
Unicode
编码
中
的BOM
一
编码
和
编码
规则 这是一个比较不好理解的东西。我们都知道计算机只认识2进制的数字0和1,任何字符在电脑
中
都是以2进制的形式存储的。把字符
转
换为计算机认识的过程就叫做
编码
,经过
编码
的字符才能被计算机处理,这时经过
编码
后的字符称之为【内码】。从前面一篇文章可以看到字符
编码
经历了ASCII、
ANSI
、UNICODE这几个阶段。所以字符
编码
就是指定文字和内码之间
转
换的一种规则,更简单的可以理解为用几个
C#
111,130
社区成员
642,541
社区内容
发帖
与我相关
我的任务
C#
.NET技术 C#
复制链接
扫一扫
分享
社区描述
.NET技术 C#
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
让您成为最强悍的C#开发者
试试用AI创作助手写篇文章吧
+ 用AI写文章


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享











