社区
脚本语言
帖子详情
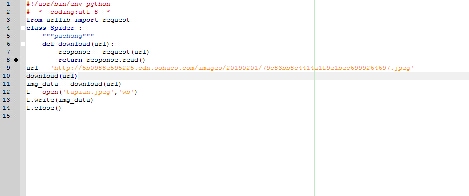
自学的Python写了个简单的爬虫~爬取图片,不知道哪出了问题,求大佬给看看
l33T.
2019-02-08 08:15:57
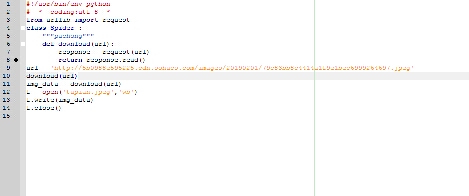
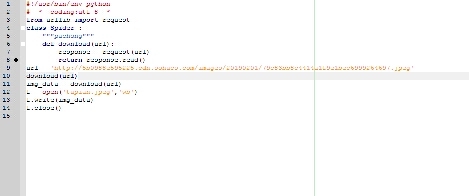
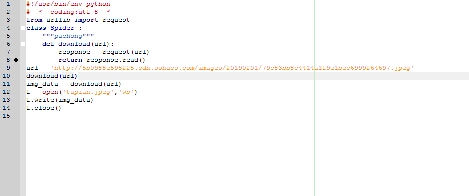
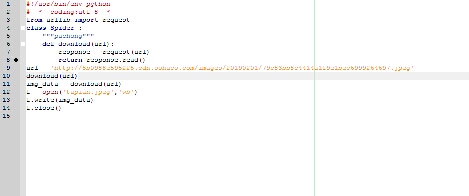
我自己的思路是先获取URL的二进制数据~然后保存成图片
...全文
357
5
打赏
收藏
自学的Python写了个简单的爬虫~爬取图片,不知道哪出了问题,求大佬给看看
我自己的思路是先获取URL的二进制数据~然后保存成图片
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
5 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
xiucai_cs
2020-02-16
打赏
举报
回复
确实看不清楚😜
susezj
2019-02-12
打赏
举报
回复
图片看不清楚
Steven·简谈
2019-02-12
打赏
举报
回复
能发个清楚的图片吗
kangxinya
2019-02-10
打赏
举报
回复
图片看不清楚
我就是玩
2019-02-09
打赏
举报
回复
图片好像看不清楚
自学
python
网络
爬虫
,从小白快速成长,分别实现静态网页爬取,下载meiztu中图片;动态网页爬取,下载burberry官网所有当季新品图片。
本文介绍了作者作为
Python
爬虫
初学者,从零开始学习
爬虫
并实现下载meizitu静态网站及burberry动态网站图片的过程。内容包括
Python
基础知识、请
求
库的使用、BeautifulSoup解析网页、动态网站的处理方法,以及如何应对网站的反爬策略。
Python
爬虫
自学
系列(一)
本文是
Python
爬虫
自学
系列的第一篇,介绍了网络
爬虫
的基本概念,包括何时使用
爬虫
、
爬虫
的合法性。讲解了封装请
求
头的重要性,通过不同场景说明请
求
头的作用,并
简单
提及了获取网页数据和网站地图。文章适合初学者入门,为后续章节奠定了基础。
python
爬虫
自学
习1+京东商品爬取实例
本文介绍如何使用
Python
的requests和BeautifulSoup库实现网页信息抓取,包括安装第三方库、请
求
网页内容、解析HTML,并通过实例展示如何爬取京东商品的价格和名称。
Python
爬虫
:爬取网页图片
本文分享了一个图片网站
爬虫
项目的实现过程,详细介绍了如何使用
Python
、requests和BeautifulSoup4等工具抓取网站数据,包括处理反爬机制、解析网页结构、保存图片资源等关键步骤。
用
python
写
一个
简单
的
爬虫
_用
Python
写
一个最
简单
的网络
爬虫
本文介绍了网络
爬虫
的基本概念及用途,并通过一个
简单
的
Python
爬虫
示例,展示如何抓取网页上的图片。从理解
爬虫
的工作原理到实现一个基本的
爬虫
脚本,读者可以学习到
爬虫
编程的基础知识。
脚本语言
37,739
社区成员
34,211
社区内容
发帖
与我相关
我的任务
脚本语言
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
复制链接
扫一扫
分享
社区描述
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
试试用AI创作助手写篇文章吧
+ 用AI写文章








 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
