本人菜鸟一只,上代码,大佬给看看。

我每天下载最新未复权行情,自己做复权处理,复权公式:复权价=收盘价*当日复权因子/最新复权因子。
下图是我本地存储的数据。adj_factor是因子列。
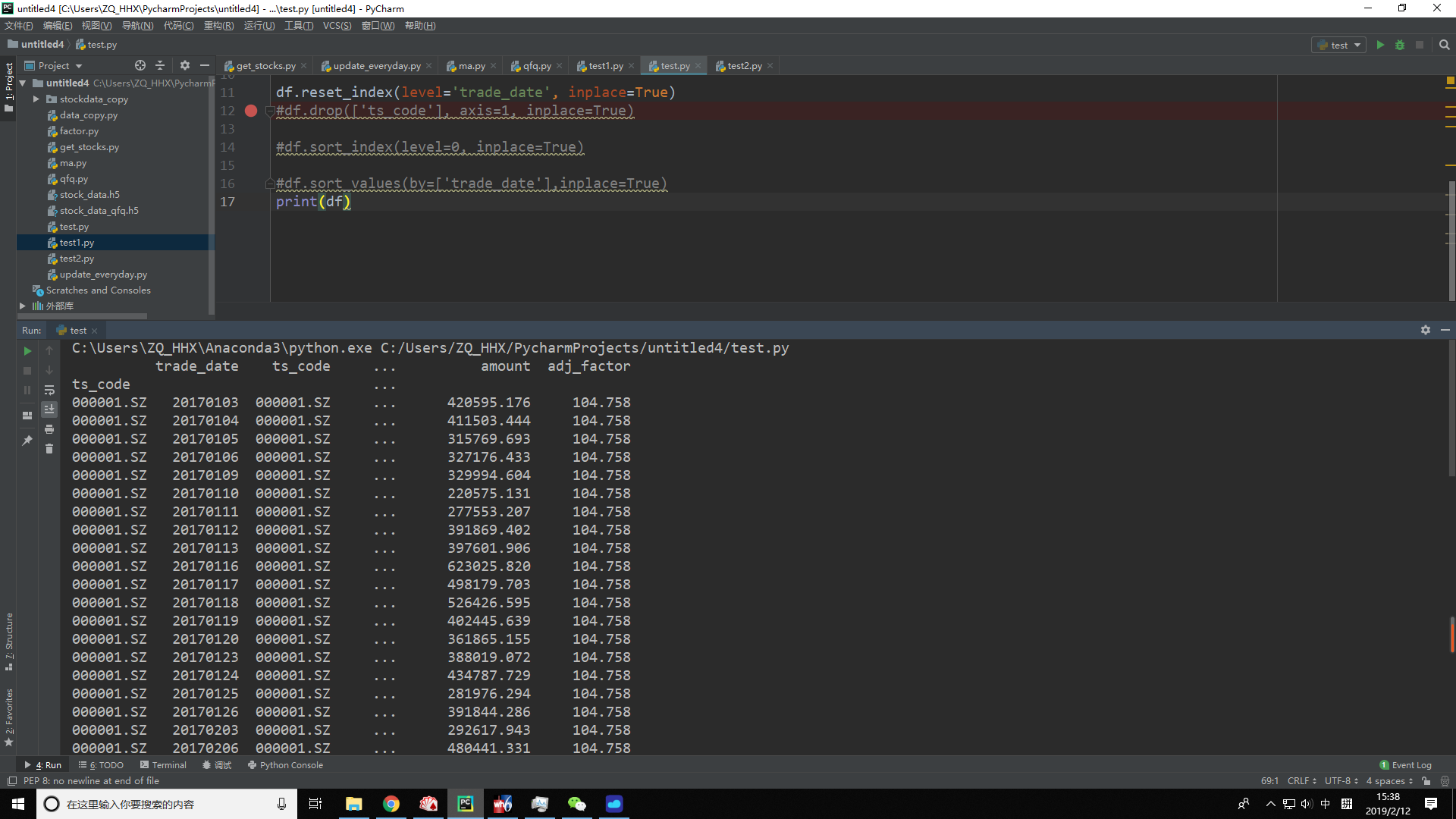
我复权处理,就是用for循环,用df1 = df.ix[code] 来保存一只股票全部代码,用i存储最新日期的因子,再用 df1['factor'] = df1['adj_factor']/i,就可以得到股票复权的系数。后面直接系列相乘,这个简单。关键是这个for循环里,1百多万行耗时8分。
网上看了很多优化的文章,才知道自己这个最愚蠢。可是按文章里说的iterrow,apply,矢量化等等,我这个很难套进去。除了我的办法之外,怎么更快速得到复权的这个系数???????????



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

