


37,719
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

 谢谢
谢谢
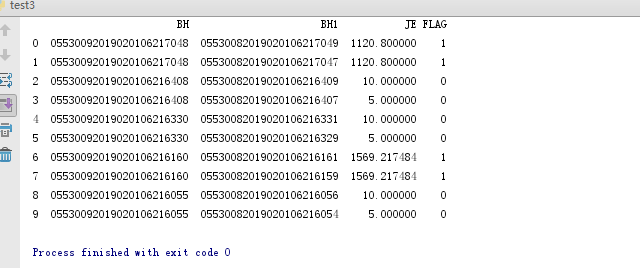
import pandas as pd
list_A = [['05530092019020106217048', '05530082019020106217049', 1120.8],
['05530092019020106217048', '05530082019020106217047', 1120.8],
['05530092019020106216408', '05530082019020106216409', 10],
['05530092019020106216408', '05530082019020106216407', 5],
['05530092019020106216330', '05530082019020106216331', 10],
['05530092019020106216330', '05530082019020106216329', 5],
['05530092019020106216160', '05530082019020106216161', 1569.217484],
['05530092019020106216160', '05530082019020106216159', 1569.217484],
['05530092019020106216055', '05530082019020106216056', 10],
['05530092019020106216055', '05530082019020106216054', 5]]
df1 = pd.DataFrame(list_A)
df1.columns = ['BH', 'BH1', 'JE']
df2 = df1.groupby(['BH']).sum().reset_index()
def get_flag(x,y):
a1 = df2[df2['BH'] == x][['JE']]
for index, row in a1.iterrows():
if row[0]/2 == y:
return "1"
else:
return "0"
df1['FLAG'] = df1.apply(lambda x: get_flag(x.BH,x.JE), axis=1)
print df1
 [/quote]
谢谢,很感谢!另外还想追问一下,如果要比较的是一组内的两个日期是否相等并作出判断,就不能用这种方式了吧,对于2019-01-01这种格式,是不是要先做转换?
[/quote]
谢谢,很感谢!另外还想追问一下,如果要比较的是一组内的两个日期是否相等并作出判断,就不能用这种方式了吧,对于2019-01-01这种格式,是不是要先做转换?
import pandas as pd
list_A = [['05530092019020106217048', '05530082019020106217049', 1120.8],
['05530092019020106217048', '05530082019020106217047', 1120.8],
['05530092019020106216408', '05530082019020106216409', 10],
['05530092019020106216408', '05530082019020106216407', 5],
['05530092019020106216330', '05530082019020106216331', 10],
['05530092019020106216330', '05530082019020106216329', 5],
['05530092019020106216160', '05530082019020106216161', 1569.217484],
['05530092019020106216160', '05530082019020106216159', 1569.217484],
['05530092019020106216055', '05530082019020106216056', 10],
['05530092019020106216055', '05530082019020106216054', 5]]
df1 = pd.DataFrame(list_A)
df1.columns = ['BH', 'BH1', 'JE']
df2 = df1.groupby(['BH']).sum().reset_index()
def get_flag(x,y):
a1 = df2[df2['BH'] == x][['JE']]
for index, row in a1.iterrows():
if row[0]/2 == y:
return "1"
else:
return "0"
df1['FLAG'] = df1.apply(lambda x: get_flag(x.BH,x.JE), axis=1)
print df1


