博主,我的毕设是这个,你这个有源码吗,我像学习一下
个人理解: 这里如果有订单才去算路径的话,性能会很差,所以我的理解是路线是先解析出来的,可以用参考oralce中递归的写法去设计一个数据模型,然后解析出大部分路线,然后如果有订单来的时候 再通过开始地点和结束地点检索出你需要的路径(经过的点最少或者经过的路程最短)
81,092
社区成员
341,718
社区内容
加载中
试试用AI创作助手写篇文章吧
 _zk 2019-02-21 04:54:44
_zk 2019-02-21 04:54:44 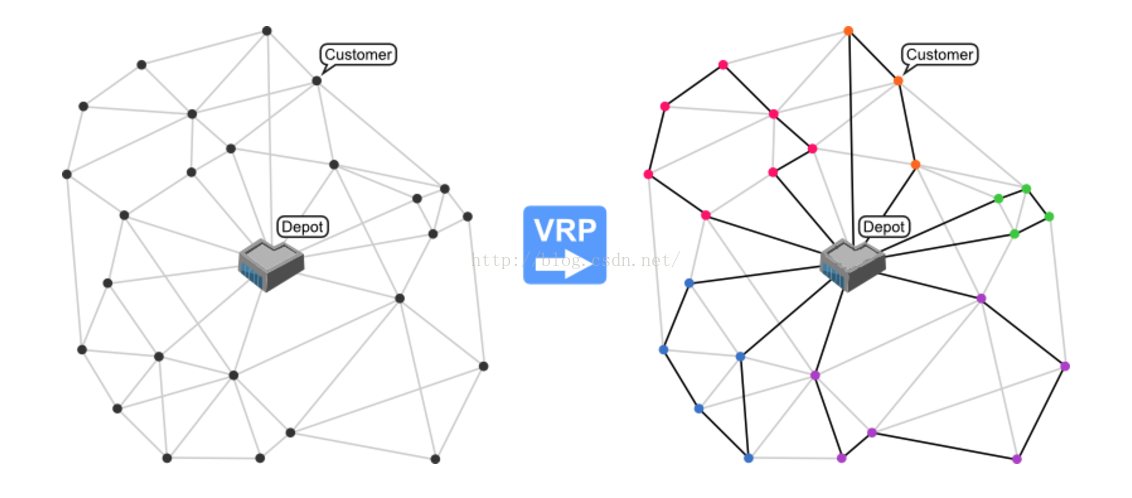



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享




