

249
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享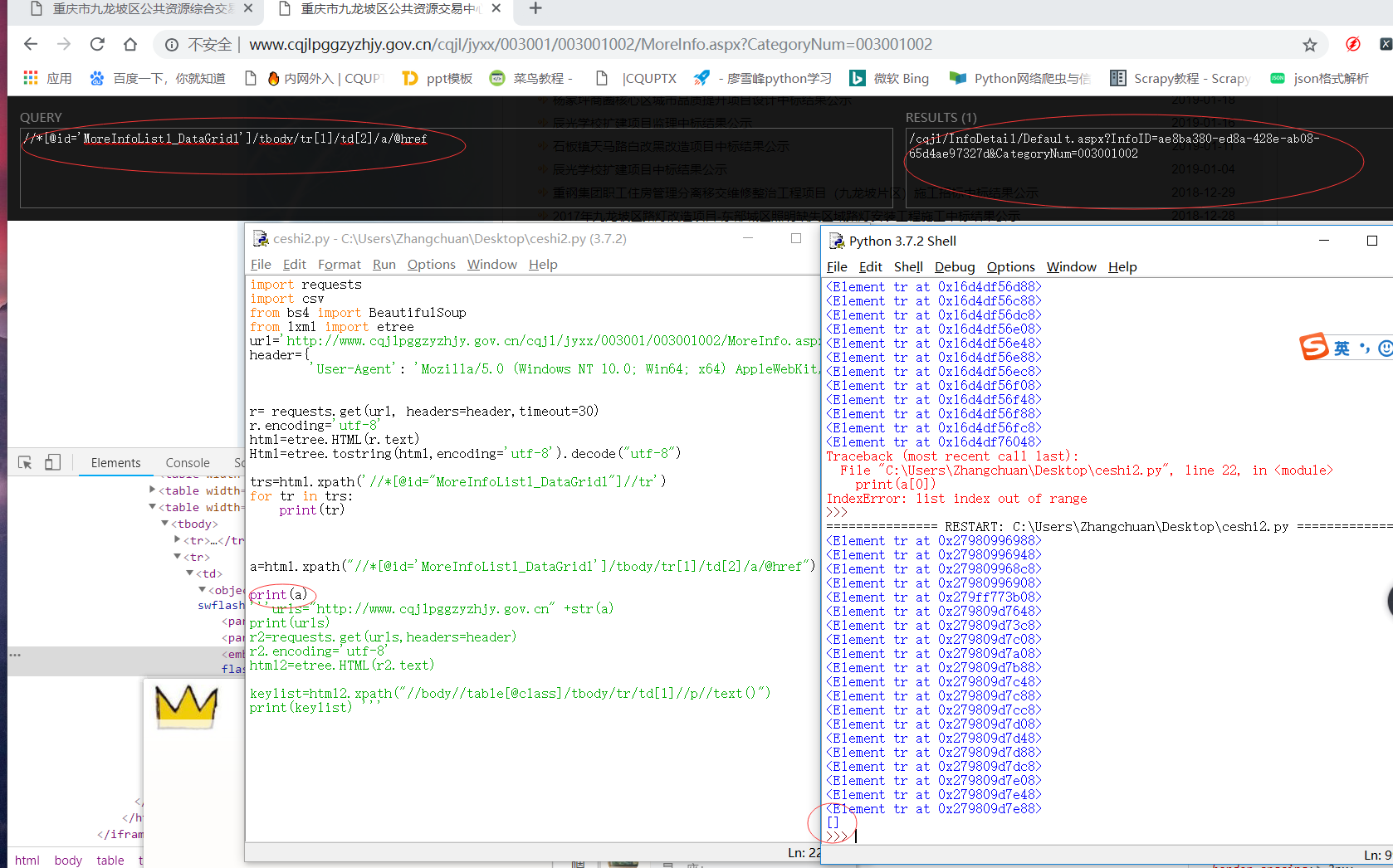
import requests
import csv
from bs4 import BeautifulSoup
from lxml import etree
url='http://www.cqjlpggzyzhjy.gov.cn/cqjl/jyxx/003001/003001002/MoreInfo.aspx?CategoryNum=003001002'
header={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'}
def main():
for i in range(1,71):
#post请求修改表单数据 只需要写要修改的部分,不需要把表单里的全部内容都写进去
playload={'__EVENTARGUMENT':i}
r = requests.post(url, headers=header, data=playload,timeout=30)
r.encoding='utf-8' #或者 r.content.decode('utf-8') html=etree.HTML(r)
html=etree.HTML(r.text)
#xpath提取tbody内的所有的tr标签,尾部没有text()
trs=html.xpath('//*[@id="MoreInfoList1_DataGrid1"]//tr')
titles=[]
messages=[]
headers=['名称','时间']
keylists=[]
valuelists=[]
#获取公告名称 和日期 ,有text()表示提取标签内的文字,而且xpath返回的就是列表
for tr in trs:
#取所有的标题名字的第一个
name=tr.xpath('.//td[2]//a//text()')[0]
#取所有日期中第一个
time=((tr.xpath('./td[3]//text()')[0]).replace('\n','')).replace('\r','')
#拼接url,并取所有url中的第一个
urls="http://www.cqjlpggzyzhjy.gov.cn" + tr.xpath(".//td[2]//a/@href/text()")[0]
r2=requests.get(urls,headers=header)
r2.encoding='utf-8'
html2=etree.HTML(r2.text)
data={'中标公告':name,
'时间':time
}
with open('九龙坡公告标题','w',encoding='utf-8',newline='') as fp:
writer=csv.DictWriter(fp,headers)
writer.writeheader()
writer.writerows(titles)
#表中的每个元素
keylist=html2.xpath("//body//table[@class]/tbody/tr/td[1]//p//text()")
for i in range(6):
keylists.append(keylist[i])
#表中每个元素对应的值
valuelist=html2.xpath("//body//table[@class]/tbody/tr/td[2]//p//text()")
for i in range(6):
valuelists.append(valuelist[i])
for i in range(6):
key=keylists[i]
value=valuelists[i]
messages[0][key]=value[0]
with open('任务2九龙坡公告内容','w',encoding='utf-8',newline='') as f:
writer=csv.DictWriter(f,headers)
writer.writeheader()
writer.writerows(messages)
main()





 [/quote]不要直接复制xpath 自己写
[/quote]不要直接复制xpath 自己写

