社区
新手乐园
帖子详情
得好大的结果
cjpp
2019-03-02 02:08:26
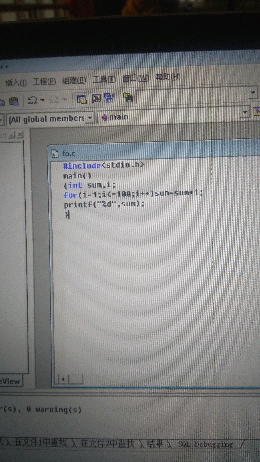
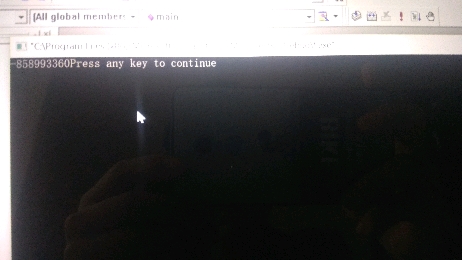
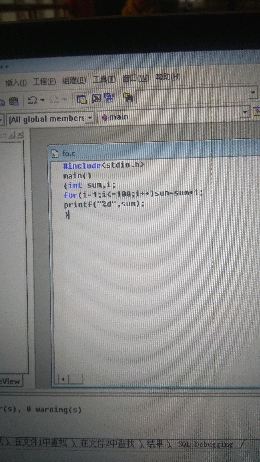
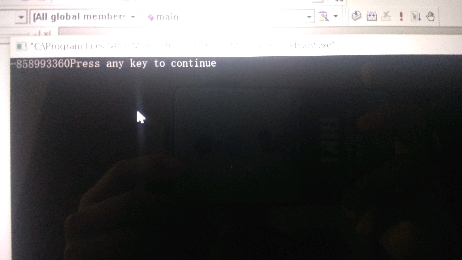
用visual c++ 6.0写了好几个程序,对了书,完全没错误,但为什么结果不对
好心人帮帮忙,谢谢
...全文
103
4
打赏
收藏
得好大的结果
用visual c++ 6.0写了好几个程序,对了书,完全没错误,但为什么结果不对 好心人帮帮忙,谢谢
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
4 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
SuMoshen
2019-03-03
打赏
举报
回复
sum赋初始值,for里面应该是i=1,不是i-1
OldHello
2019-03-03
打赏
举报
回复
赋值一个初始值
cjpp
2019-03-03
打赏
举报
回复
不好意思,第一次发这个,没注意,没办法了,等我再有的点积分再发了
636f6c696e
2019-03-02
打赏
举报
回复
自己发帖麻烦看看显示效果,能看清么?
大规模数据处理计算引擎Spark2.x教程(含资料)
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。本部分内容全面涵盖了Spark生态系统的概述及其编程模型,深入内核的研究,Spark on Yarn,Spark RDD、Spark Streaming流式计算原理与实践,Spark SQL,Spark的多语言编程以及SparkR的原理和运行。本套Spark教程不仅面向项目开发人员,甚至对于研究Spark的在校学员,都是非常值得学习的。
left join的优化,小的结果集驱动大的结果集
left join 的时间开销类似于笛卡尔积,相当费时,如果关联字段是索引字段,可以减少时间复杂度,但是还是非常费时。 left 的优化:首先,mysql都是使用(Nested Loop )循环套嵌的方式实现join,这里包括两个部分:驱动表结果集作为条件连接被驱动表X,被驱动表根据驱动表结果查询数据集Y。时间复杂度(X*Y),这里的第二部分是数据库内部的操作,涉及io,cpu等的操作很少,而且...
计算机主板大小性能区别,电脑主板是大板好还是小板好 主板中大板和小板的区别介绍...
在DIY装机选择主板的时候,经常会有用户问小编这样一个问题:电脑主板大板好还是小板好?对于此问题,笔者也经常会不厌其烦的为装机用户简单解答一下,不过问的朋友多了,难免会有些反感,今天脚本之家小编为大家详细罗列一下主板大板和小板的区别,希望大家在装机选主板的时候,能够从容的选择。首先笔者来让大家看看时下流行的B85小板与小板的结果区别,笔者这里以华硕B85-PLUS大板和华硕B85M-E小板为例,先...
sql2008还原数据库失败,因为结果数据库的累积大小超出10240MB许可限制值。
sql2008还原数据库失败,因为结果数据库的累积大小超出10240MB许可限制值。 今天碰到一个问题,我装的是sql2008 r2 epress 版本,结果在还原超过10G的一个数据库时,就报错,提示 数据库的累积大小超过许可限制。 解决方案:直接将epress版本升级到专业版就好 配置中心---》sql安装中心 ------》维护-----》版本升级,
神经网络训练多个epoch,写论文的时候可以取最好的效果那一个epoch作为结果吗?
论文中一般都是用在**验证集上效果最好的模型去预测测试集,多次预测的结果取平均计算准确率或者mAP值而不是单纯的取一次最好的结果作为论文的结果。**如果你在写论文的过程中,把测试集当做验证集去验证的话,这其实是作假的,建议不要这样,一旦有人举报或者复现出来你的结果和你论文中的结果相差很大的话,是会受到很大处分的。 我之前曾遇到过这种情况,我在图像分类的过程中曾经用过CutMix增强方式,CutMix其实就是将两张图片放在一起,如下图所示,这种结果会造成验证集上准确率很大的波动,可能一会儿变成99%,一会儿变
新手乐园
33,311
社区成员
41,784
社区内容
发帖
与我相关
我的任务
新手乐园
C/C++ 新手乐园
复制链接
扫一扫
分享
社区描述
C/C++ 新手乐园
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章
 好心人帮帮忙,谢谢
好心人帮帮忙,谢谢



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



