本人查阅资料 网上所说需要解密两次js加密 用解密后的结果放到cookie里面再去请求就能正常获取到html
问题一:我用的http请求代码 怎么才能返回给我结果,现在直接会跳到catch里面
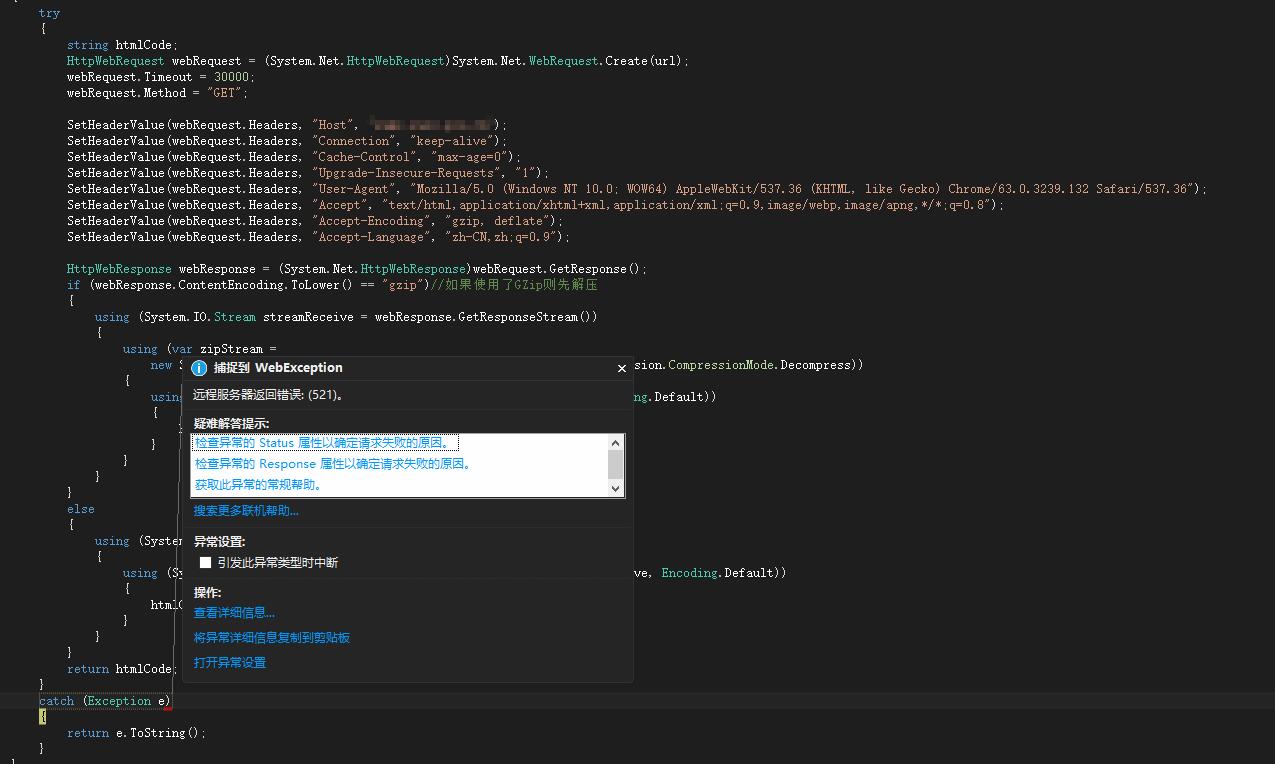
代码:
try
{
string htmlCode;
HttpWebRequest webRequest = (System.Net.HttpWebRequest)System.Net.WebRequest.Create(url);
webRequest.Timeout = 30000;
webRequest.Method = "GET";
SetHeaderValue(webRequest.Headers, "Host", "");//这里我就不显示啦
SetHeaderValue(webRequest.Headers, "Connection", "keep-alive");
SetHeaderValue(webRequest.Headers, "Cache-Control", "max-age=0");
SetHeaderValue(webRequest.Headers, "Upgrade-Insecure-Requests", "1");
SetHeaderValue(webRequest.Headers, "User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36");
SetHeaderValue(webRequest.Headers, "Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8");
SetHeaderValue(webRequest.Headers, "Accept-Encoding", "gzip, deflate");
SetHeaderValue(webRequest.Headers, "Accept-Language", "zh-CN,zh;q=0.9");
HttpWebResponse webResponse = (System.Net.HttpWebResponse)webRequest.GetResponse();
if (webResponse.ContentEncoding.ToLower() == "gzip")//如果使用了GZip则先解压
{
using (System.IO.Stream streamReceive = webResponse.GetResponseStream())
{
using (var zipStream =
new System.IO.Compression.GZipStream(streamReceive, System.IO.Compression.CompressionMode.Decompress))
{
using (StreamReader sr = new System.IO.StreamReader(zipStream, Encoding.Default))
{
htmlCode = sr.ReadToEnd();
}
}
}
}
else
{
using (System.IO.Stream streamReceive = webResponse.GetResponseStream())
{
using (System.IO.StreamReader sr = new System.IO.StreamReader(streamReceive, Encoding.Default))
{
htmlCode = sr.ReadToEnd();
}
}
}
return htmlCode;
}
catch (Exception e)
{
return e.ToString();
}
我应该怎样做才能 的到结果的 就是网上所的那段js 我去在线请求get的网站测试 那个网站是能返回js的 求大神教下 或者发个请求代码



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享





