:[\s\S]*?$
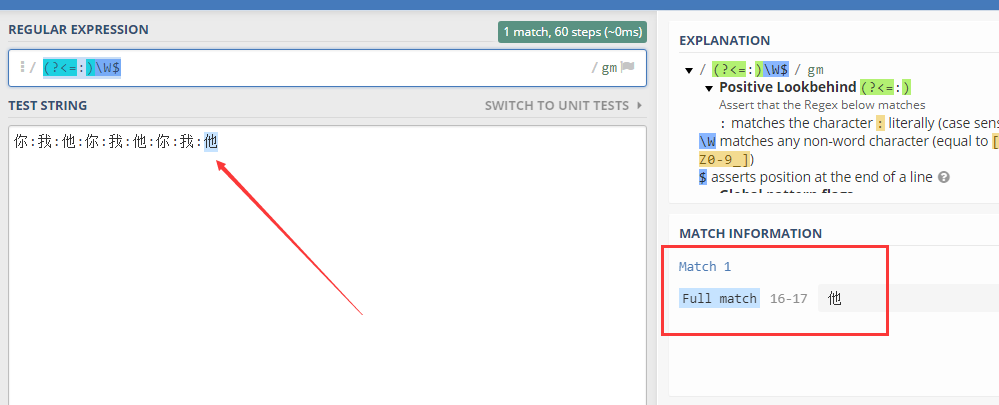
(?<=我:).*?$
(?<=:)[^:]+(?=$)
[quote=引用 4 楼 兔子党-督察 的回复:] (?<=:)[^:]+(?=$)
System.Text.RegularExpressions.Regex.Matches(txt,@"", System.Text.RegularExpressions.RegexOptions.RightToLeft)
真心求教,不费话 如下字符串“你:我:他" 现想单独提取最后一个冒号后的内容 下面正则表达式:[\s\S]*?$提取的是“我:他” 我想要的结果就是“他”,请高手指点
111,129
社区成员
642,541
社区内容
加载中
让您成为最强悍的C#开发者
试试用AI创作助手写篇文章吧


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享