社区
脚本语言
帖子详情
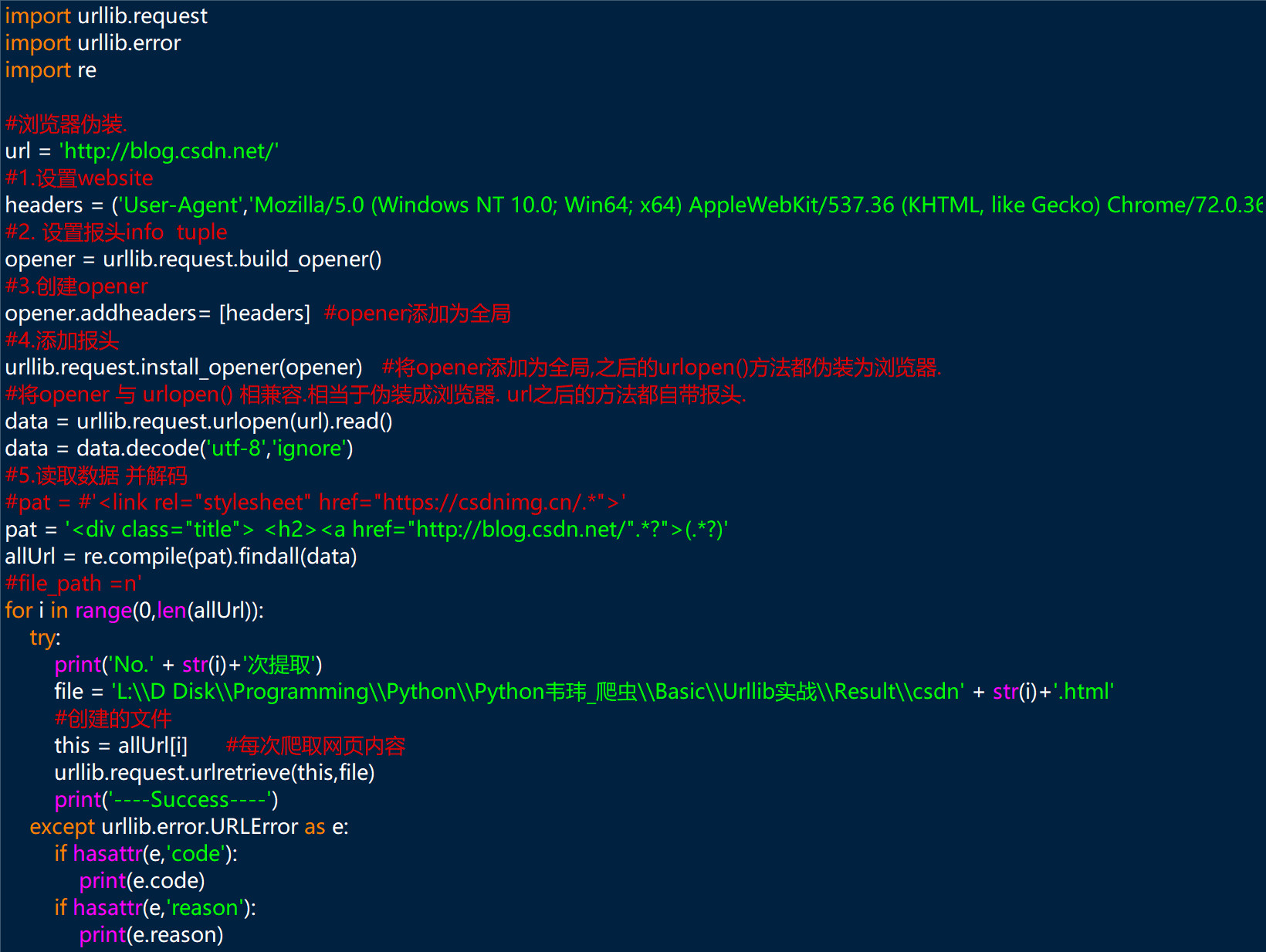
Python 以浏览器伪装技术爬取网站首页的链接,查看网页源代码如图所示,如何写正则表达式?
LeafDream_
2019-03-22 08:13:29
感觉是正则那里出了问题,爬不到内容。
第一张图为随意选取的网页,第二张图为选取网页的标签,第三张图为代码。不知道是不是正则表达式书写错误, 运行不报错也爬不到相应内容。
...全文
309
3
打赏
收藏
Python 以浏览器伪装技术爬取网站首页的链接,查看网页源代码如图所示,如何写正则表达式?
感觉是正则那里出了问题,爬不到内容。 第一张图为随意选取的网页,第二张图为选取网页的标签,第三张图为代码。不知道是不是正则表达式书写错误, 运行不报错也爬不到相应内容。
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
3 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
LeafDream_
2019-03-24
打赏
举报
回复
学框架前想把底层的细节给弄清楚,希望能指点下。 ajax反扒我没做,但是应该不用做也可以爬取到网页。但是程序没报错,估计是正则那里分析出错了。但是按照内容所在的相邻标签将内容替换成(.*?),我理解上是可以的。
荇䔽Boso
2019-03-22
打赏
举报
回复
一般用框架去爬没那么多问题
我电脑上有一整套现成的代码,你改下就能用那种
可惜,火车上wifi渣帮不了你
荇䔽Boso
2019-03-22
打赏
举报
回复
做了ajax反扒吧?
Python
网络爬虫和
正则表达式
学习总结
阅读目录 1.利用urllib2对指定的URL抓取
网页
内容 2. 使用
正则表达式
过滤抓取到的
网页
信息 2.1
正则表达式
介绍 2.2
Python
的re模块 2.3
Python
正则表达式
汇总 以前在学校做科研都是直接利用网上共享的一些数据,就像我们经常说的dataset、beachmark等等。但是,对于实际的工业需求来说,
爬取
网络的数据是必须的并且是首要的。最近在国内一家互联网公司实习,我的mentor交给我的第一件事就是去网络上
爬取
数据,并对
爬取
的数据进行相关的分析和解析。 很多人学习
爬虫笔记1 requests获取
网页
源代码
与
正则表达式
处理文本
@兰博怎么玩儿 爬虫笔记1 第一个爬虫程序和BeautifulSoup解析库 接触爬虫不久,特利用此笔记记录一下爬虫学习过程和心得,如有错误请批评指正。 本文介绍:利用BeautifulSoup解析库,
爬取
起点中文网(https://www.qidian.com/rank/yuepiao?style=2)中“原创风云榜”榜单数据。 1、准备
python
版本 3.5.0 安装第三方库:re...
超详细解析
python
爬虫
爬取
京东图片
超详细图片爬虫实战实例讲解(京东商城手机图片
爬取
)1.创建一个文件夹来存放你
爬取
的图片2.第一部分代码分析3.第二部分代码分析完整的代码如下所示:升级版代码:
爬取
过程中首先你需要观察在手机页面变化的过程来使用
正则表达式
匹配源码中图片的
链接
然后在保存到本地 其次就是信息过滤,出除了你需要的手机图片以外的其他信息过滤掉:可通过
查看
网页
代码找到图片的起始以及结束的代码
爬取
过程: 1)建立一个
爬取
图片...
Python
爬取
豆瓣电影top250
我的目录1.准备工作1.1、安装
Python
2.1建立jupyter环境3.1进入编辑环境2.分析
网页
2.1 打开豆瓣电影top250
网页
2.2 分析
网页
结构2.3 用for循环分析结果2.4 用page函数表示这十页的URL
链接
3.
爬取
网页
3.1 请求HTML
源代码
3.2 到TOP250上对代码进行审查3.3 请求
网页
及请求方法3.4
伪装
浏览器
4.信息筛选4.1 安装lxml库4.2 过滤4....
python
爬取
大众点评数据_
python
爬虫实例详细介绍之
爬取
大众点评的数据
python
爬虫实例详细介绍之
爬取
大众点评的数据一.
Python
作为一种语法简洁、面向对象的解释性语言,其便捷性、容易上手性受到众多程序员的青睐,基于
python
的包也越来越多,使得
python
能够帮助我们实现越来越多的功能。本文主要介绍如何利用
python
进行网站数据的抓取工作。我看到过利用c++和Java进行爬虫的代码,c++的代码很复杂,而且可读性、可理解性较低,不易上手,一般是那些高手用...
脚本语言
37,720
社区成员
34,238
社区内容
发帖
与我相关
我的任务
脚本语言
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
复制链接
扫一扫
分享
社区描述
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
试试用AI创作助手写篇文章吧
+ 用AI写文章


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



 我电脑上有一整套现成的代码,你改下就能用那种
我电脑上有一整套现成的代码,你改下就能用那种 可惜,火车上wifi渣帮不了你
可惜,火车上wifi渣帮不了你

