社区
脚本语言
帖子详情
爬取淘宝评论时只能爬取99页,后面的全是和99页一样的,怎么解决啊
bite the dust
2019-04-08 03:48:21
有没有大神帮忙,还是只能100页
...全文
371
2
打赏
收藏
爬取淘宝评论时只能爬取99页,后面的全是和99页一样的,怎么解决啊
有没有大神帮忙,还是只能100页
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
2 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
此账号已关闭
2019-04-09
打赏
举报
回复
应该是cookie 限制吧,看一看你的源代码
bite the dust
2019-04-08
打赏
举报
回复
引用 楼主 bite the dust的回复:
有没有大神帮忙,还是只能100页
能不能把几万条数据都爬出来?
爬取
安居客上的出租房信息,并通过
爬取
的数据进行数据清洗以及数据分析.rar
这个爬虫是我前段
时
间在
淘宝
上做单子的
时
候遇见的一个客户需求。本来以为就是一个简单的爬虫项目。但
后面
客户加了数据清洗和数据分析的要求。而后又加了要详细代码解释的需求等等。直到最后客户坦白说这是他们大专的毕设.......但是这个单子坐下来只有200左右,我想了一下,感觉好亏啊。在
淘宝
上随便找一个做毕设的都要好多钱的,而且客户本身的代码能力、数学、逻辑能力都很差,导致我每行都给注释以及看不懂,在我交付代码后又纠缠了我一个多礼拜。反正总体做下来的感觉就是烦躁。头一次感觉到了客户需求变更带来的巨大麻烦。 总之这是一次不是很愉快的爬虫经历。但是作为我写爬虫以来注释最详细的一次,以及第一次真正使用像matplotlib这种数据分析库的代码,我认为还是有必要分享出来给大家当个参考的(PS:大佬轻拍~)。爬虫本身几乎没有什么难度,写的也比较乱,敬请见谅。
爬取
安居客上的出租房信息(武汉地区的),并通过
爬取
的数据进行数据清洗以及数据分析。给出四个不同层面的可视化图
安居客出租房(武汉为例)爬虫+数据分析+可视化
### 安居客出租房(武汉为例)爬虫+数据分析+可视化 这个爬虫是我前段
时
间在
淘宝
上做单子的
时
候遇见的一个客户需求。本来以为就是一个简单的爬虫项目。但
后面
客户加了数据清洗和数据分析的要求。而后又加了要详细代码解释的需求等等。直到最后客户坦白说这是他们大专的毕设.......但是这个单子坐下来只有200左右,我想了一下,感觉好亏啊。在
淘宝
上随便找一个做毕设的都要好多钱的,而且客户本身的代码能力、数学、逻辑能力都很差,导致我每行都给注释以及看不懂,在我交付代码后又纠缠了我一个多礼拜。反正总体做下来的感觉就是烦躁。头一次感觉到了客户需求变更带来的巨大麻烦。 总之这是一次不是很愉快的爬虫经历。但是作为我写爬虫以来注释最详细的一次,以及第一次真正使用像matplotlib这种数据分析库的代码,我认为还是有必要分享出来给大家当个参考的(PS:大佬轻拍~)。爬虫本身几乎没有什么难度,写的也比较乱,敬请见谅。 **功能**
爬取
安居客上的出租房信息(武汉地区的),并通过
爬取
的数据进行数据清洗以及数据分析。给出四个不同层面的可视化图。最终结果如下图所示: 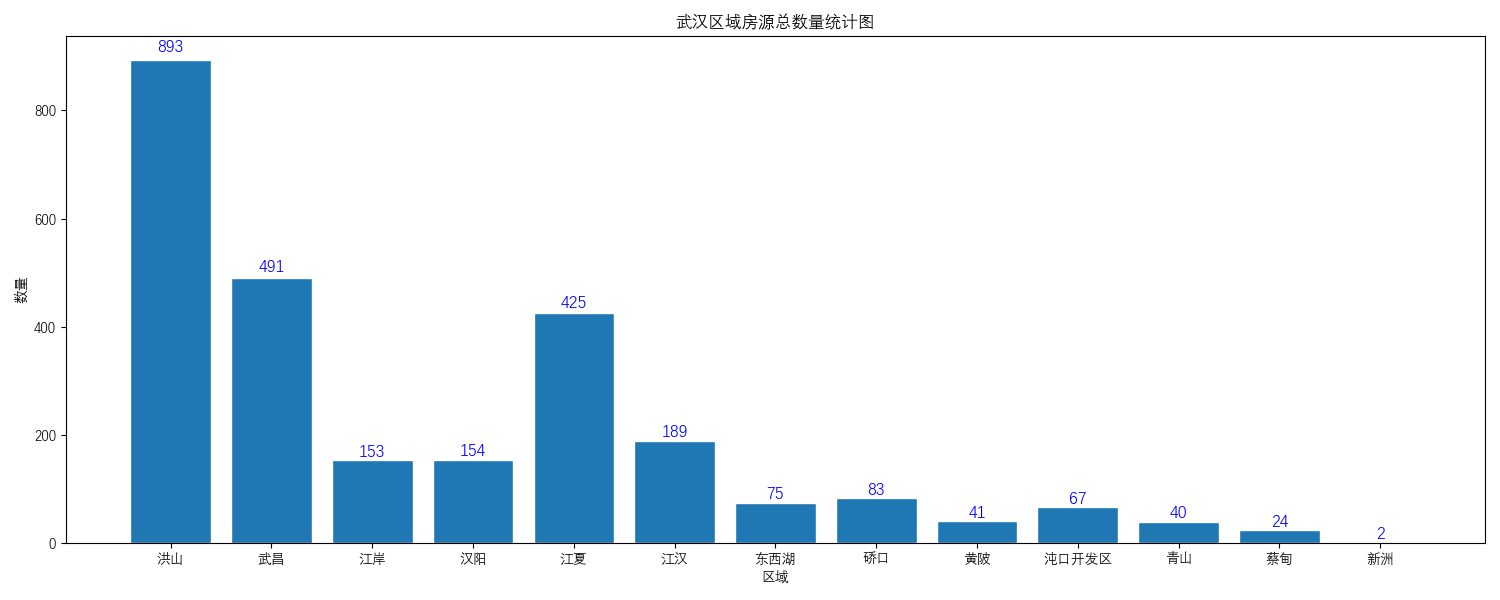 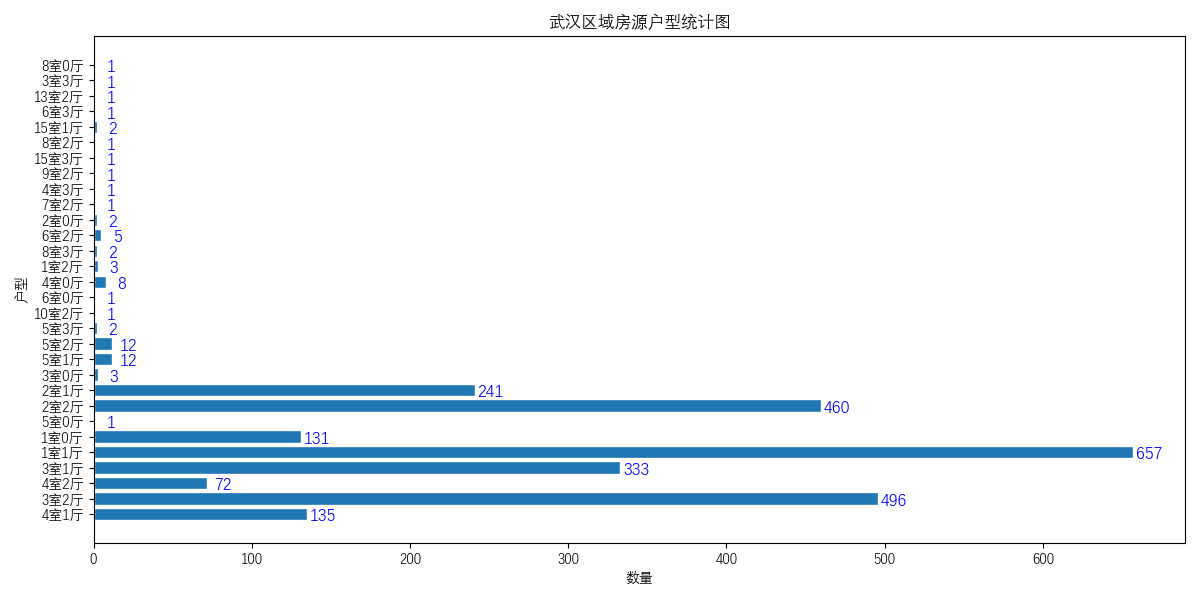 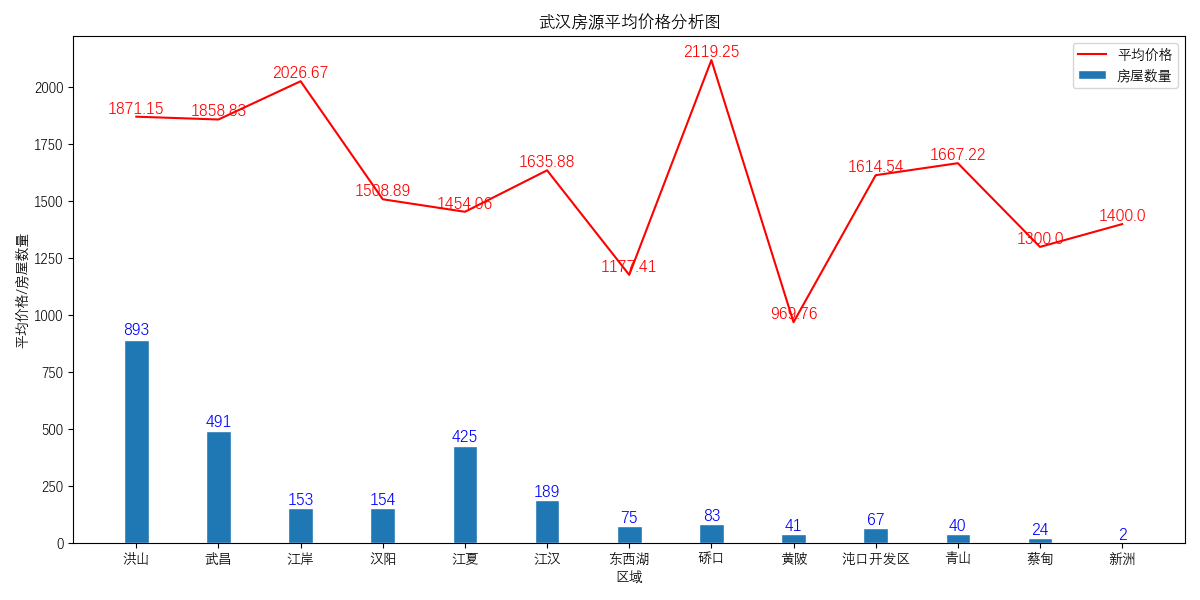  **环境** 1. Windows 10 2. python3.7 **使用方法** 首先声明该爬虫由于是特定情况下写的,所以本身的通用性特别差,仅可以对安居客网站上的武汉的出租房信息进行
爬取
,且需要自己手动更新cookie。同
时
在对数据进行分析及可视化的
时
候由于也是特别针对武汉出租房的进行的,所以针对性也比较强。如果别的需求需要自己进行更改。 1. 访问[安居客网址](https://wuhan.anjuke.com/),获取cookie。 > tip:获取cookie的方法可根据[此链接](https://jingyan.baidu.com/article/5d368d1ea6c6e33f60c057ef.html) 2. 在项目中找到`spider.py`的文件,将第12行的cookie换成你自己的cookie。 3. 运行`spider.py`,获取房源信息。运行后应会产生一个`武汉出租房源情况.csv`的文件。此文件为我们从安居客上
爬取
的房源信息,其中包含`房屋租住链接、房屋描述、房屋地址、房屋详情(户型)以及经纪人、房屋价格`五个属性。 4. 在获取了数据之后我们运行`matplotlib.py`文件。进行数据清洗,分析,可视化。运行后即可获得**功能**中展示四个图片。 **技术栈** 1. request 2. parsel 3. pandas 4. matplotlib **进步(相比之前)** 此次爬虫相比之前的技术上可以说有减无增。但其中注释相当详细,可谓是每行代码都有注释。所以对于初学者应该有一些用处。同
时
使用matplotlib进行了数据分析可视化等。对于数据处理的代码的注释也是几乎每行都有注释的。
Python爬虫之
爬取
淘女郎照片示例详解
本篇目标 抓取
淘宝
MM的姓名,头像,年龄 抓取每一个MM的资料简介以及写真图片 把每一个MM的写真图片按照文件夹保存到本地 熟悉文件保存的过程 1.URL的格式 在这里我们用到的URL是 http://mm.taobao.com/json/request_top_list.htm?page=1,问号前面是基地址,
后面
的参数page是代表第几
页
,可以随意更换地址。点击开之后,会发现有一些
淘宝
MM的简介,并附有超链接链接到个人详情
页
面。 我们需要抓取本
页
面的头像地址,MM姓名,MM年龄,MM居住地,以及MM的个人详情
页
面地址。 2.抓取简要信息 相信大家经过上几次的实战,对抓取和
tmImage:一个
淘宝
图片获取项目
1.通过访问
淘宝
传输图片的js来获取链接地址下载图片。 2.链接地址由三部分拼接而成,分别是通过分析不变的前半部分和后半部分以及jsonp
后面
的参数以及tce_sid
后面
的参数这里初步确定为目标服务器进程号和子进程号。 使用: 1:通过人为输入json_pid和tce_sid 2:通过输入的json_pid和tce_sid来进行拆分目标的url,来进行
爬取
v1.0版本功能不够完善的api接口的交流谢谢合作联系v:
【爬虫】Python
爬取
电商平台
评论
目前网站上很多
爬取
评论
的博文都已经失效了,所以自己尝试写一篇目前可行的
爬取
代码。我们以
爬取
淘宝
的APPLE官方旗舰店的Iphone11为例。 打开
淘宝
页
面,按下F12快捷键,进入开发者模式。点击累计评价。然后在开发者窗口左上角输入list,找到相应的进程。 这里发现了
评论
。寻找请求头headers信息。找到请求的url,发现其中只有三个参数是会改变的。发现其中的规律。 首先是"currentP...
脚本语言
37,719
社区成员
34,238
社区内容
发帖
与我相关
我的任务
脚本语言
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
复制链接
扫一扫
分享
社区描述
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


