110,536
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享ALTER PROCEDURE [dbo].[QuaintTest]
@rtn int output
AS
DECLARE @Piece_Id INT, @Piece_PId INT ,@Piece_Level INT,@Piece_Time DATETIME
BEGIN
SET NOCOUNT ON;
DECLARE
@cuisor_b_val CURSOR --创建游标变量
DECLARE cursor_B CURSOR --创建动态游标
FOR SELECT Piece_Id,Piece_PId,Piece_Level,Piece_Time
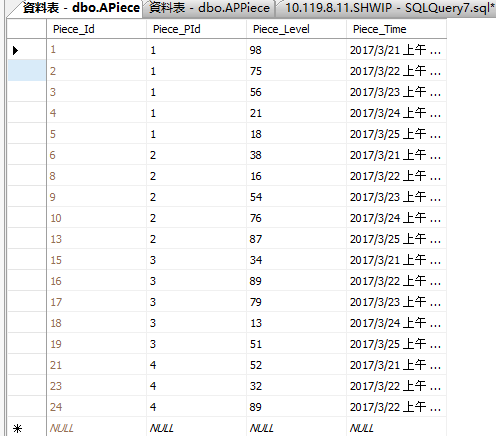
FROM APiece; --创建游标接受结果集
OPEN cursor_B --打开游标
fetch next from cursor_B INTO @Piece_Id,@Piece_PId,@Piece_Level,@Piece_Time --into的变量数量必须与游标查询结果集的列数相同
--0,Fetch语句成功。
--1:Fetch语句失败或行不在结果集中。
--2:提取的行不存在。
WHILE @@FETCH_STATUS=0 --判断FETCH语句是否执行成功
BEGIN
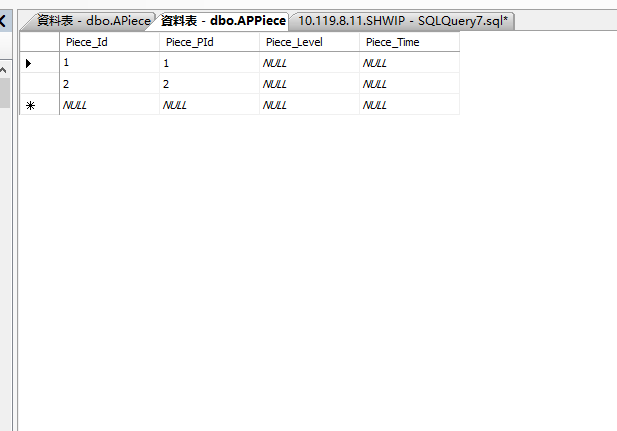
if exists(select * from APPiece where Piece_Id=@Piece_Id)
begin
UPDATE dbo.APPiece SET Piece_PId = @Piece_PId,Piece_Level=@Piece_Level,Piece_Time=@Piece_Time where Piece_Id=@Piece_Id
set @rtn=1 --有身份证相同的数据,进行更新处理
end
else
begin
insert into dbo.APPiece(Piece_Id,Piece_PId,Piece_Level,Piece_Time) values(@Piece_Id,@Piece_PId,@Piece_Level,@Piece_Time)
set @rtn=2 --没有相同的数据,进行插入处理
end
fetch next from cursor_B INTO @Piece_Id,@Piece_PId,@Piece_Level,@Piece_Time --移动游标
END
CLOSE cursor_B --关闭游标
DEALLOCATE cursor_B; --释放游标
END