社区
脚本语言
帖子详情
大佬们,Python用余弦算法计算相似度后,怎么计算召回率和精确率
qq_41037648
2019-04-10 06:41:49
...........
...全文
661
3
打赏
收藏
大佬们,Python用余弦算法计算相似度后,怎么计算召回率和精确率
...........
复制链接
扫一扫
分享
转发到动态
举报
AI
作业
写回复
配置赞助广告
用AI写文章
3 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
zhulin0909
2020-03-22
打赏
举报
回复
zhulin0909
2020-03-22
打赏
举报
回复
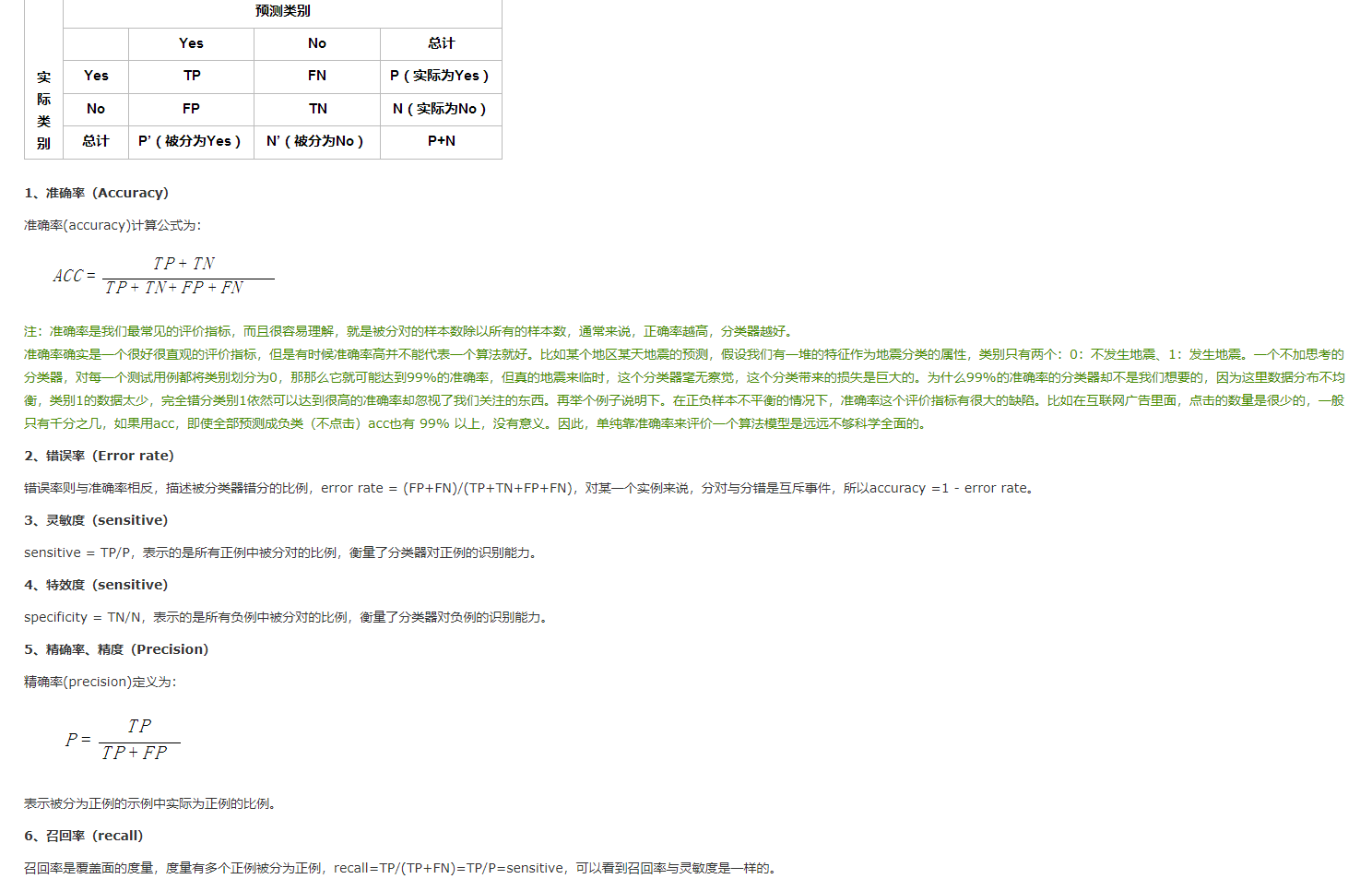
根据召回率和精确率的公式应该不难写出来
weixin_43903601
2020-03-20
打赏
举报
回复
请问你知道该如何实现了吗,我现在也遇到了这个问题,不知道如何计算召回率和准确率,还希望得到大佬指点,
召回率
Recall原理与代码实例讲解
召回率
(Recall)是信息检索、推荐系统、图像识别等领域的核心指标之一,用以衡量模型找到所有相关结果的能力。良好的
召回率
意味着模型能够涵盖尽可能多的正确答案,减少误判和遗漏。在自然语言处理领域,
召回率
更是...
推荐
算法
面经整理
召回 -> 精排 -> 多目标混排推荐的模型发展过程 LR widedeep 多任务(PLE详细解释) 多场景等召回排序有哪些模型?具体是干什么的?协同过滤是怎么样的?召回策略,协同过滤,关键词召回召回的多样性双塔模型优势,...
计算
机视觉
算法
岗面试题
大佬
的面试经验:https://www.nowcoder.com/discuss/128148 以及
大佬
的博客:https://blog.csdn.net/liuxiao214/article/details/83043170
Python
基础学完了再学什么?
基础阶段学完
Python
基础语法、
python
容器、函数和文件操作、面向对象、
python
编程和web基础、Linux 操作系统多任务编程、
Python
网络编程、静态 web 服务器、HTML、CSS、JavaScript、数据库MySQL、正则表达式、...
Python
基础学完了之后陷入迷茫?今天这篇文章让你明白基础学完该学的内容
基础阶段学完
Python
基础语法、
python
容器、函数和文件操作、面向对象、
python
编程和web基础、Linux 操作系统多任务编程、
Python
网络编程、静态 web 服务器、HTML、CSS、JavaScript、数据库MySQL、正则表达式、...
脚本语言
37,743
社区成员
34,211
社区内容
发帖
与我相关
我的任务
脚本语言
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
复制链接
扫一扫
分享
社区描述
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
试试用AI创作助手写篇文章吧
+ 用AI写文章


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享